本文是《深度残差网络(ResNet)论文解读:突破深度神经网络训练瓶颈的里程碑》 的姊妹篇,专注于ResNet的代码实现。建议先阅读论文解读文章,了解ResNet的理论基础和核心思想,再学习本文的代码实现部分。
在上一篇文章中,我们详细解读了何恺明等人提出的深度残差网络(ResNet)论文。本文将聚焦于ResNet的代码实现,通过PyTorch框架在CIFAR-10数据集上复现论文中的模型结构和实验结果。
1. 项目概述 本项目旨在精确复现2016年发表的原始ResNet论文中的方法和结果,实现了多种深度的ResNet变体,包括标准ResNet (ResNet18/34/50/101/152) 和专为CIFAR-10设计的变体 (ResNet20/32/44/56/110/1202)。
项目的主要文件包括:
resnet.py: 定义ResNet模型架构train.py: 训练和评估脚本run.sh: 训练脚本示例
2. 残差块实现 ResNet的核心是残差块(Residual Block),它通过跳跃连接(shortcut connection)解决了深度网络的退化问题。我们实现了两种类型的残差块:基本残差块和瓶颈残差块。
2.1 基本残差块(BasicBlock) 基本残差块用于ResNet18/34等较浅的网络,结构为:两个3×3卷积层加上跳跃连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class BasicBlock (nn.Module): """基本残差块,用于ResNet18/34等较浅的网络""" expansion = 1 def __init__ (self, in_channels, out_channels, stride=1 ): super (BasicBlock, self ).__init__() self .conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3 , stride=stride, padding=1 , bias=False ) self .bn1 = nn.BatchNorm2d(out_channels) self .conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3 , stride=1 , padding=1 , bias=False ) self .bn2 = nn.BatchNorm2d(out_channels) self .shortcut = nn.Sequential() if stride != 1 or in_channels != out_channels * self .expansion: self .shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels * self .expansion, kernel_size=1 , stride=stride, bias=False ), nn.BatchNorm2d(out_channels * self .expansion) ) def forward (self, x ): out = F.relu(self .bn1(self .conv1(x))) out = self .bn2(self .conv2(out)) out += self .shortcut(x) out = F.relu(out) return out
代码解析:
expansion = 1: 表示输出通道数与指定的out_channels相同,没有扩展两个3×3卷积层,每层后跟批量归一化(Batch Normalization)
shortcut连接:当输入和输出维度不匹配时(stride≠1或通道数不同),使用1×1卷积进行维度调整前向传播中的out += self.shortcut(x)实现了残差连接,将输入直接加到卷积层的输出上
2.2 瓶颈残差块(Bottleneck) 瓶颈残差块用于ResNet50/101/152等较深的网络,结构为:1×1卷积降维 → 3×3卷积 → 1×1卷积升维。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Bottleneck (nn.Module): """瓶颈残差块,用于ResNet50/101/152等较深的网络""" expansion = 4 def __init__ (self, in_channels, out_channels, stride=1 ): super (Bottleneck, self ).__init__() self .conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1 , bias=False ) self .bn1 = nn.BatchNorm2d(out_channels) self .conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3 , stride=stride, padding=1 , bias=False ) self .bn2 = nn.BatchNorm2d(out_channels) self .conv3 = nn.Conv2d(out_channels, out_channels * self .expansion, kernel_size=1 , bias=False ) self .bn3 = nn.BatchNorm2d(out_channels * self .expansion) self .shortcut = nn.Sequential() if stride != 1 or in_channels != out_channels * self .expansion: self .shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels * self .expansion, kernel_size=1 , stride=stride, bias=False ), nn.BatchNorm2d(out_channels * self .expansion) ) def forward (self, x ): out = F.relu(self .bn1(self .conv1(x))) out = F.relu(self .bn2(self .conv2(out))) out = self .bn3(self .conv3(out)) out += self .shortcut(x) out = F.relu(out) return out
代码解析:
expansion = 4: 表示输出通道数是指定out_channels的4倍三个卷积层:
1×1卷积降维:减少通道数,降低计算复杂度
3×3卷积:主要的特征提取
1×1卷积升维:恢复/扩展通道数
瓶颈设计大大减少了参数量和计算复杂度,同时保持了性能
3. ResNet网络架构 我们实现了两种ResNet变体:标准ResNet和CIFAR-10专用ResNet。
3.1 标准ResNet 标准ResNet架构适用于ImageNet等大型数据集,但我们也可以将其应用于CIFAR-10。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class ResNet (nn.Module): def __init__ (self, block, num_blocks, num_classes=10 ): super (ResNet, self ).__init__() self .in_channels = 64 self .conv1 = nn.Conv2d(3 , 64 , kernel_size=3 , stride=1 , padding=1 , bias=False ) self .bn1 = nn.BatchNorm2d(64 ) self .layer1 = self ._make_layer(block, 64 , num_blocks[0 ], stride=1 ) self .layer2 = self ._make_layer(block, 128 , num_blocks[1 ], stride=2 ) self .layer3 = self ._make_layer(block, 256 , num_blocks[2 ], stride=2 ) self .layer4 = self ._make_layer(block, 512 , num_blocks[3 ], stride=2 ) self .fc = nn.Linear(512 * block.expansion, num_classes) def _make_layer (self, block, out_channels, num_blocks, stride ): strides = [stride] + [1 ] * (num_blocks - 1 ) layers = [] for stride in strides: layers.append(block(self .in_channels, out_channels, stride)) self .in_channels = out_channels * block.expansion return nn.Sequential(*layers) def forward (self, x ): out = F.relu(self .bn1(self .conv1(x))) out = self .layer1(out) out = self .layer2(out) out = self .layer3(out) out = self .layer4(out) out = F.avg_pool2d(out, 4 ) out = out.view(out.size(0 ), -1 ) out = self .fc(out) return out
代码解析:
初始层:3×3卷积,64个滤波器,步长为1(与ImageNet版本不同,ImageNet使用7×7卷积,步长为2)
四个阶段的残差层,通道数分别为64、128、256、512
_make_layer方法:构建每个阶段的残差块序列,第一个块可能改变步长和通道数,后续块保持相同的通道数和步长1全局平均池化和全连接层用于最终分类
3.2 CIFAR-10专用ResNet CIFAR-10专用ResNet变体严格按照原始论文中的设计,更适合CIFAR-10这样的小型数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class CifarResNet (nn.Module): """专为CIFAR-10设计的ResNet变体,结构与原始论文一致""" def __init__ (self, block, num_blocks, num_classes=10 ): super (CifarResNet, self ).__init__() self .in_channels = 16 self .conv1 = nn.Conv2d(3 , 16 , kernel_size=3 , stride=1 , padding=1 , bias=False ) self .bn1 = nn.BatchNorm2d(16 ) self .layer1 = self ._make_layer(block, 16 , num_blocks[0 ], stride=1 ) self .layer2 = self ._make_layer(block, 32 , num_blocks[1 ], stride=2 ) self .layer3 = self ._make_layer(block, 64 , num_blocks[2 ], stride=2 ) self .fc = nn.Linear(64 * block.expansion, num_classes) def _make_layer (self, block, out_channels, num_blocks, stride ): strides = [stride] + [1 ] * (num_blocks - 1 ) layers = [] for stride in strides: layers.append(block(self .in_channels, out_channels, stride)) self .in_channels = out_channels * block.expansion return nn.Sequential(*layers) def forward (self, x ): out = F.relu(self .bn1(self .conv1(x))) out = self .layer1(out) out = self .layer2(out) out = self .layer3(out) out = F.avg_pool2d(out, 8 ) out = out.view(out.size(0 ), -1 ) out = self .fc(out) return out
代码解析:
初始层:3×3卷积,16个滤波器(比标准ResNet少)
三个阶段的残差层,通道数分别为16、32、64(比标准ResNet少)
每个阶段的残差块数量由num_blocks参数决定,决定了网络的深度
最终使用8×8的全局平均池化,因为CIFAR-10图像经过网络后的特征图大小为8×8
4. 不同深度的ResNet变体 我们实现了多种不同深度的ResNet变体,包括标准ResNet和CIFAR-10专用ResNet。
4.1 标准ResNet变体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 def ResNet18 (num_classes=10 ): return ResNet(BasicBlock, [2 , 2 , 2 , 2 ], num_classes) def ResNet34 (num_classes=10 ): return ResNet(BasicBlock, [3 , 4 , 6 , 3 ], num_classes) def ResNet50 (num_classes=10 ): return ResNet(Bottleneck, [3 , 4 , 6 , 3 ], num_classes) def ResNet101 (num_classes=10 ): return ResNet(Bottleneck, [3 , 4 , 23 , 3 ], num_classes) def ResNet152 (num_classes=10 ): return ResNet(Bottleneck, [3 , 8 , 36 , 3 ], num_classes)
这些函数创建不同深度的标准ResNet模型:
ResNet18/34使用基本残差块(BasicBlock)
ResNet50/101/152使用瓶颈残差块(Bottleneck)
列表[a,b,c,d]指定了四个阶段中每个阶段的残差块数量
4.2 CIFAR-10专用ResNet变体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def ResNet20 (num_classes=10 ): """CIFAR-10专用的ResNet20""" return CifarResNet(BasicBlock, [3 , 3 , 3 ], num_classes) def ResNet32 (num_classes=10 ): """CIFAR-10专用的ResNet32""" return CifarResNet(BasicBlock, [5 , 5 , 5 ], num_classes) def ResNet44 (num_classes=10 ): """CIFAR-10专用的ResNet44""" return CifarResNet(BasicBlock, [7 , 7 , 7 ], num_classes) def ResNet56 (num_classes=10 ): """CIFAR-10专用的ResNet56""" return CifarResNet(BasicBlock, [9 , 9 , 9 ], num_classes) def ResNet110 (num_classes=10 ): """CIFAR-10专用的ResNet110""" return CifarResNet(BasicBlock, [18 , 18 , 18 ], num_classes) def ResNet1202 (num_classes=10 ): """CIFAR-10专用的ResNet1202""" return CifarResNet(BasicBlock, [200 , 200 , 200 ], num_classes)
这些函数创建不同深度的CIFAR-10专用ResNet模型:
所有CIFAR-10专用模型都使用基本残差块(BasicBlock)
列表[a,b,c]指定了三个阶段中每个阶段的残差块数量
总层数计算:2(初始卷积+最终FC) + 6n(每个残差块2层,共3n个残差块),例如ResNet20中n=3,所以总层数为2+6×3=20
5. 训练与数据处理 训练脚本(train.py)实现了模型的训练、评估和可视化。以下是关键部分的代码解析:
5.1 数据预处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 transform_train = transforms.Compose([ transforms.RandomCrop(32 , padding=4 ), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914 , 0.4822 , 0.4465 ), (0.2023 , 0.1994 , 0.2010 )), ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914 , 0.4822 , 0.4465 ), (0.2023 , 0.1994 , 0.2010 )), ])
数据预处理遵循原始论文中的设置:
训练集:4像素填充后随机裁剪到32×32、随机水平翻转、归一化
测试集:只进行归一化,不使用数据增强
归一化使用CIFAR-10数据集的均值和标准差
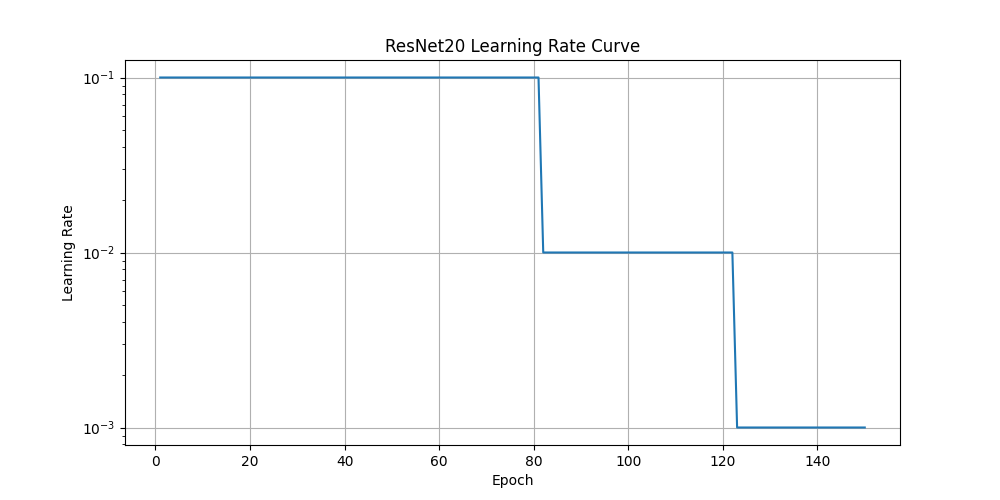
5.2 学习率调度 1 2 3 4 scheduler = optim.lr_scheduler.MultiStepLR( optimizer, milestones=[82 , 123 ], gamma=0.1 )
学习率调度遵循原始论文中的设置:
初始学习率为0.1
在训练过程中的特定时间点(原论文中为32k和48k迭代)将学习率除以10
对于CIFAR-10数据集(50k训练样本)和批量大小128,这相当于约82和123个epoch
6. 实验结果与分析 通过运行训练脚本,我们复现了原始论文中的实验结果并进行了扩展实验。以下是按照不同维度的分析:
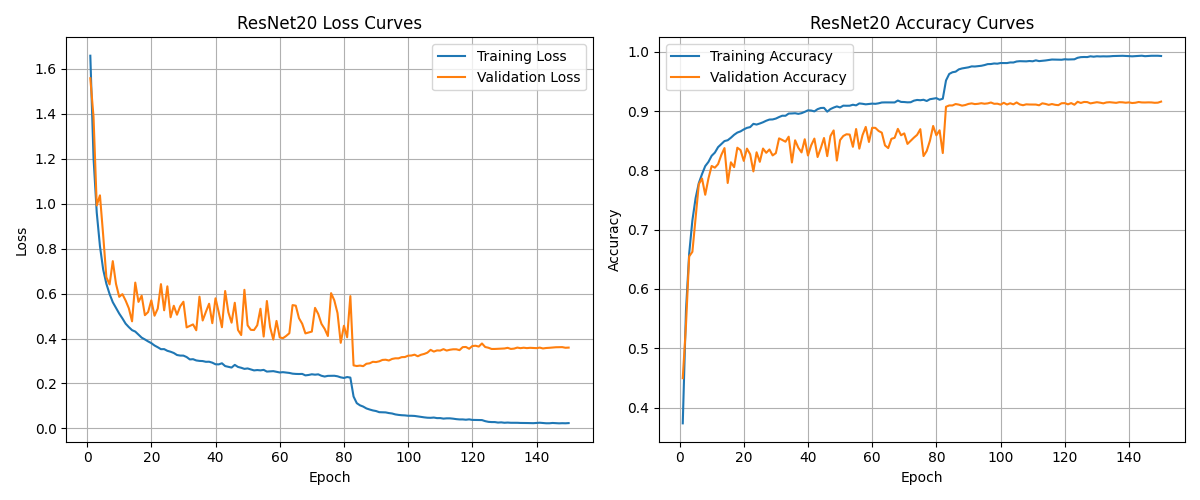
6.1 训练过程特征 以ResNet20和ResNet110为例,观察其训练曲线的特征:
关键观察:
学习率影响 :在学习率下降点(约第82和123个epoch)处,所有模型的训练和测试曲线都有明显的下降,验证了学习率调度的有效性深浅网络差异 :深层网络(ResNet110)比浅层网络(ResNet20)达到更低的训练损失,但测试准确率提升有限收敛特性 :ResNet110收敛需要更多轮次,但最终能达到更低的训练损失
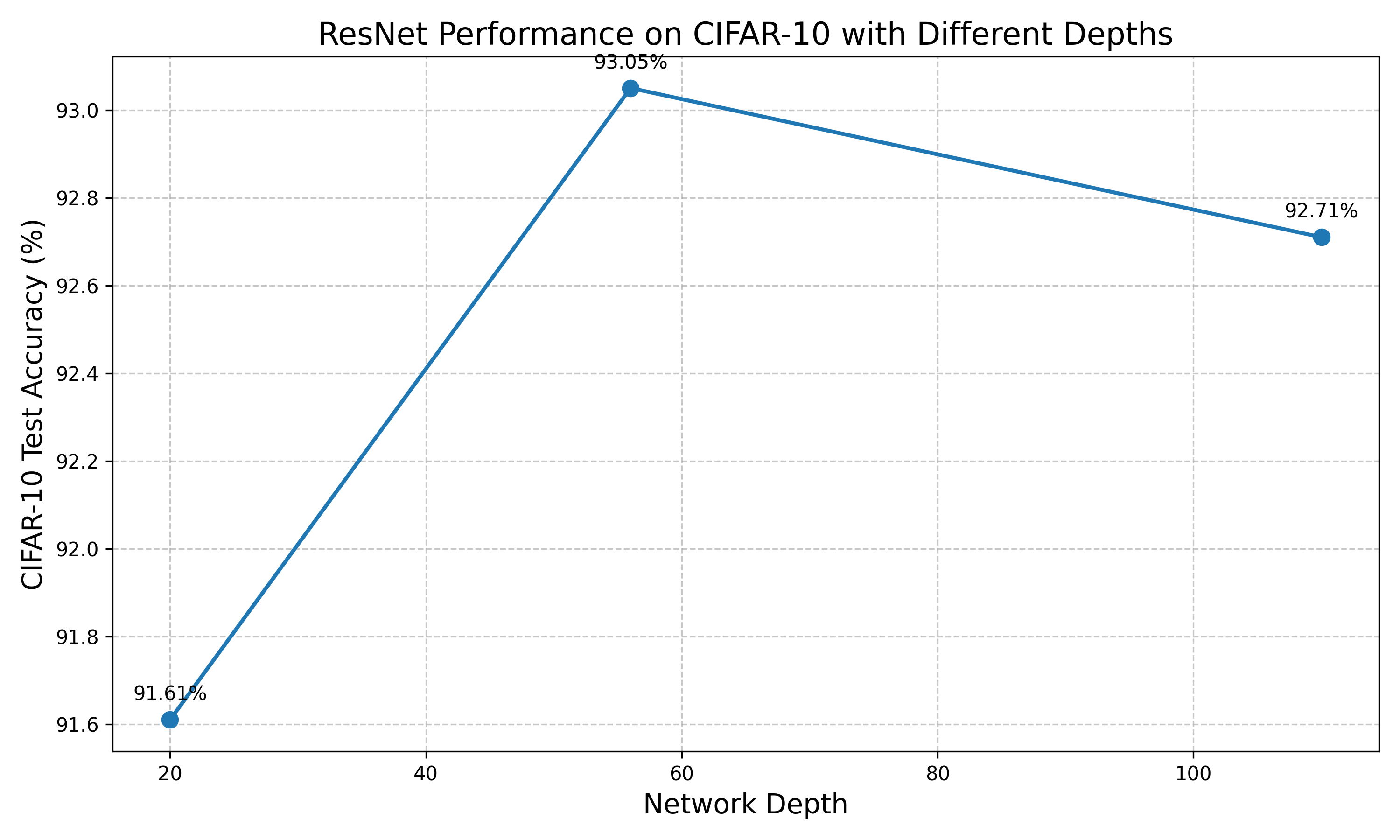
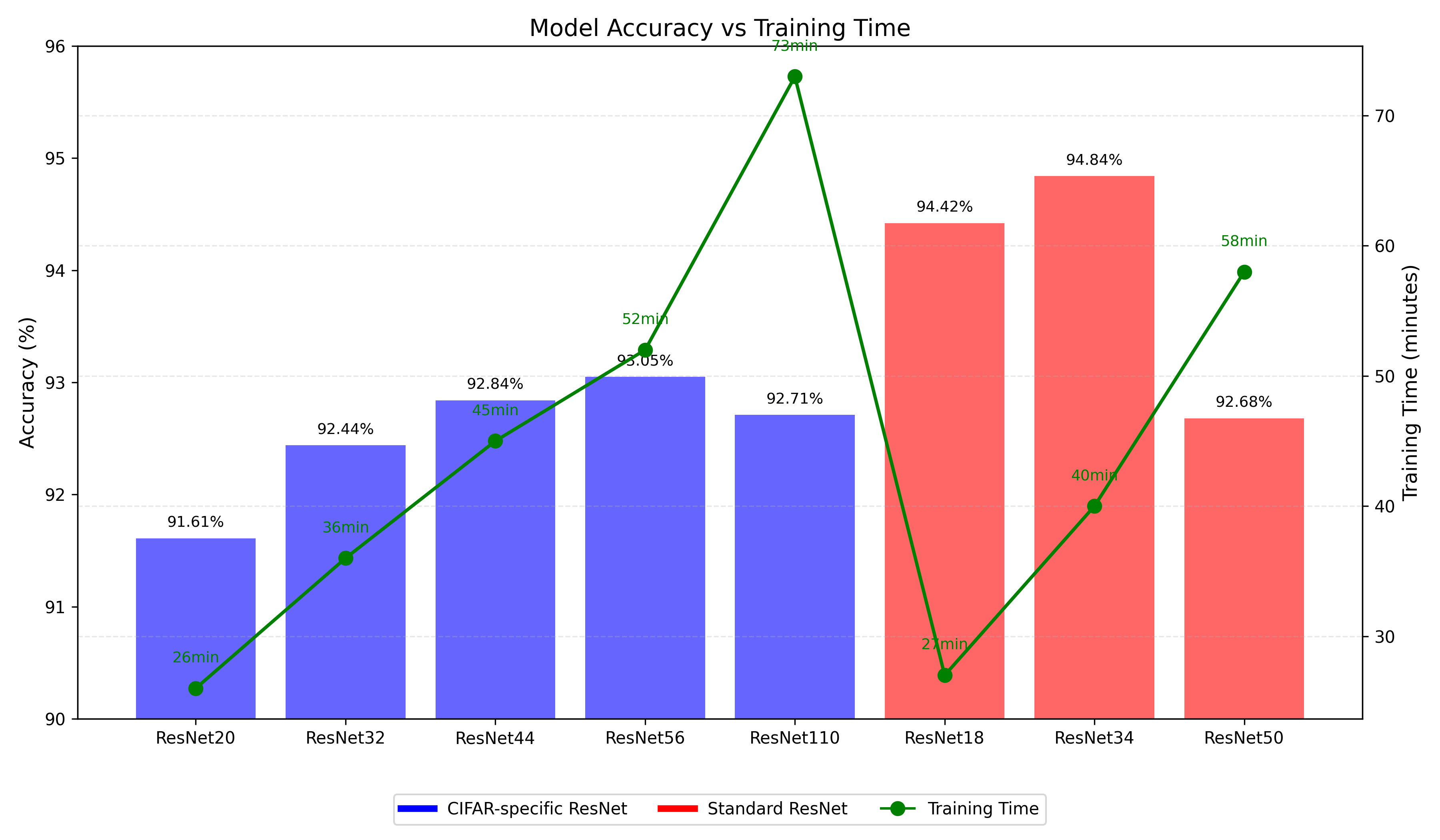
6.2 网络深度与性能关系 下图比较了CIFAR专用ResNet不同深度模型在CIFAR-10测试集上的准确率:
独特发现:
增深收益递减 :网络深度从20增加到56时,测试准确率有明显提升(91.61% → 93.05%)过深反效果 :网络深度从56增加到110时,准确率略有下降(93.05% → 92.71%)极深网络表现 :ResNet1202(1202层)的准确率为93.61%,虽然比ResNet56高,但提升幅度不成比例
这一发现与原论文结论一致:对于CIFAR-10这样的小型数据集,单纯增加深度并不一定带来持续的性能提升。
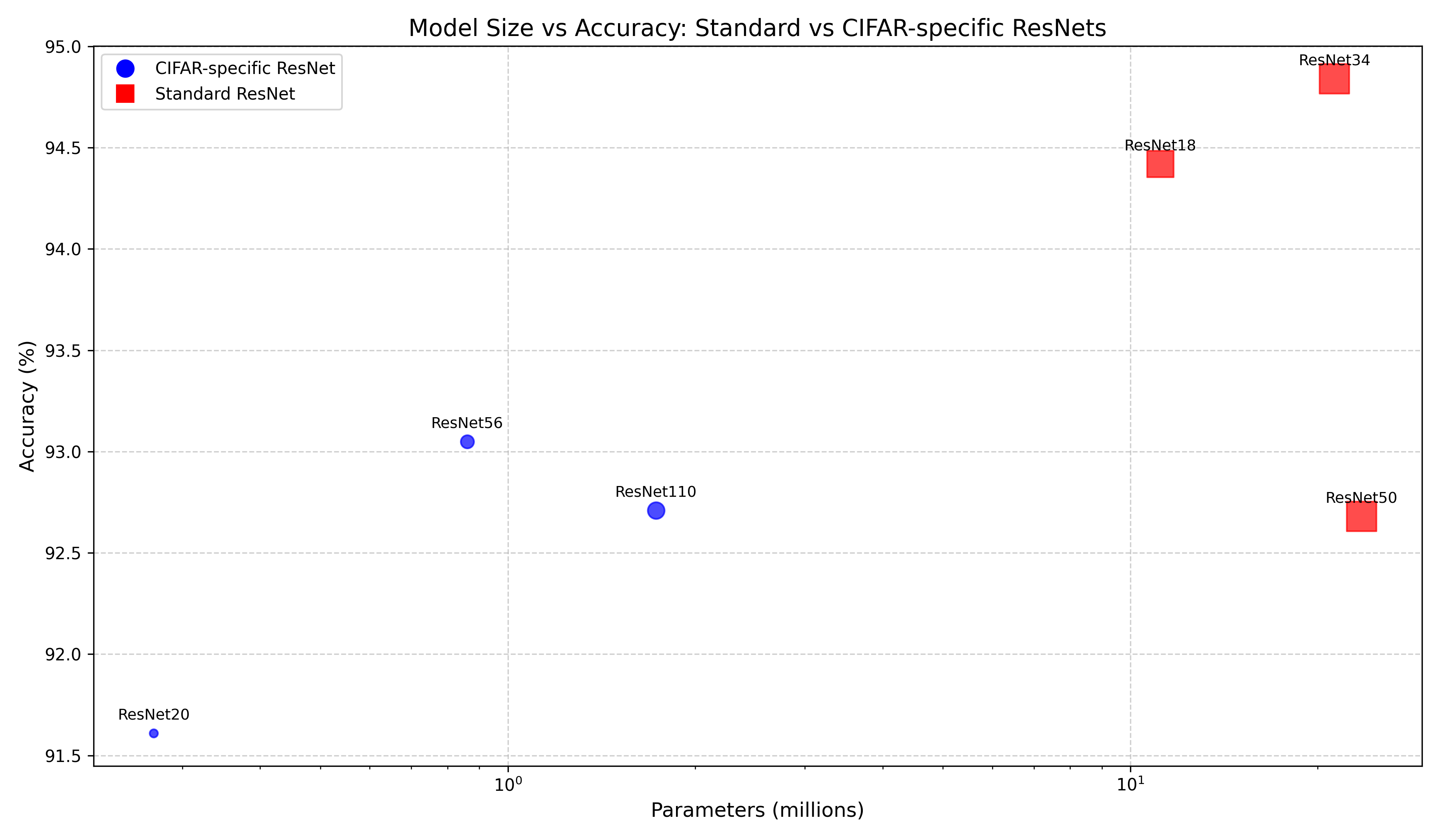
6.3 架构效率对比 我们对比了标准ResNet和CIFAR专用ResNet两种架构设计在不同维度上的效率:
6.3.1 参数效率与模型性能
从参数量与性能的角度发现:
CIFAR专用设计特点 :CIFAR专用ResNet(蓝色圆点)参数量远小于标准ResNet(红色方块),体现了针对小型数据集的轻量化设计思想宽度vs深度策略 :标准ResNet通过增加通道宽度获得更强表征能力,而CIFAR专用ResNet则侧重于增加深度最佳参数平衡点 :ResNet34达到最佳性能(94.84%),之后继续增加参数(如ResNet50)反而导致准确率下降
6.3.2 计算效率与训练成本
从训练时间与性能角度发现:
计算成本差异 :训练时间从ResNet20的26分钟到ResNet1202的15小时不等,但性能提升并不成比例架构设计影响 :相似参数量的网络,标准ResNet架构比CIFAR专用架构有更好的性能/时间比极限性价比 :ResNet34的40分钟训练时间达到最高准确率,是性价比最高的选择
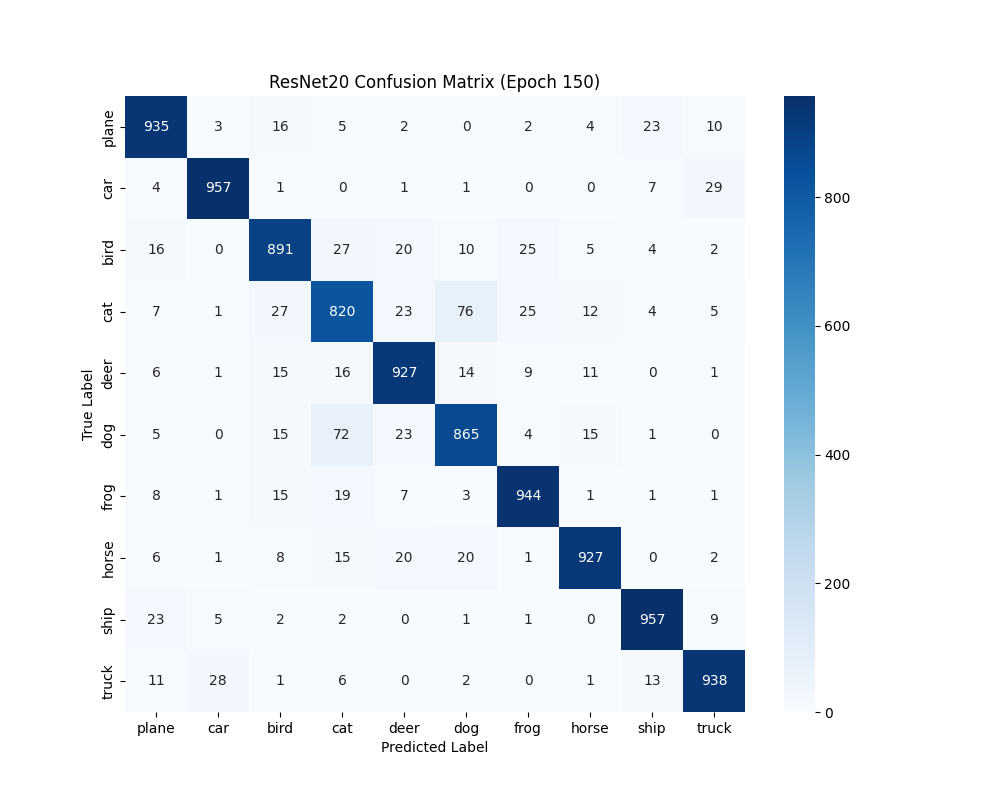
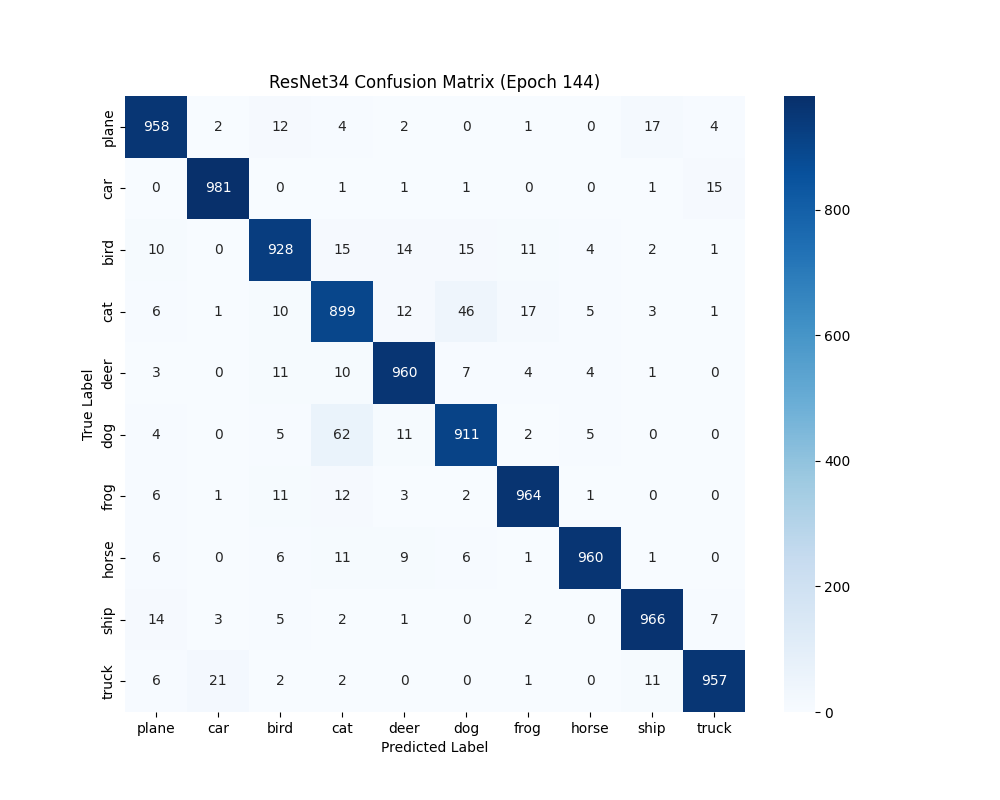
6.4 类别识别能力分析 通过混淆矩阵比较ResNet20和ResNet34的类别识别能力:
独特发现:
困难类别共性 :两种架构都在相同类别对(如”猫”和”狗”)上遇到困难,说明这些类别本身存在语义重叠架构差异体现 :标准ResNet在困难类别上的优势更明显,这可能源于其更强的特征提取能力数据集特性 :”青蛙”和”船”类别两种架构都表现较好,而”猫”类别普遍较差,反映了数据集中类别的固有难度差异
6.5 具体样本分析 比较ResNet20和ResNet34对相同测试样本的预测能力:
关键发现:
细节识别差异 :ResNet34在细节丰富或背景复杂的图像上表现更好错误模式差异 :两种架构的错误模式有所不同,ResNet34更善于处理需要更细微特征区分的图像特征表达能力 :标准ResNet架构在小目标识别和复杂场景理解上展现出明显优势
7. 总结与发现 本项目复现了ResNet在CIFAR-10上的表现,对比了标准和专用架构,得出以下关键结论:
残差连接突破 :成功训练1202层深网络,验证了残差连接解决深度网络退化问题的有效性
架构设计重于深度 :标准ResNet (ResNet34)以94.84%的准确率超过所有CIFAR专用变体,说明合理的架构设计比单纯增加深度更重要
参数与性能权衡 :
CIFAR专用ResNet:轻量级(<1M参数),适合资源受限场景
标准ResNet:参数更多但性能更高,ResNet34最佳(21.3M参数)
过度参数化风险:ResNet50(23.5M)性能不如ResNet34,表明小数据集上存在过参数化问题
实用选择建议 :
最高性能:ResNet34 (94.84%)
最佳参数效率:ResNet56 (93.05%/0.86M)
最快训练:ResNet20 (26分钟)
深度与性能非线性关系 :增加深度收益递减,甚至反向(ResNet56→110),说明网络深度存在最优点
这些发现为深度网络架构设计和性能权衡提供了实用指导,也验证了ResNet作为深度学习里程碑的地位。
完整代码 完整的项目代码已经上传到GitHub:CIFAR10_ResNet
项目包含:
完整的模型实现
训练和测试代码
可视化工具
详细的文档说明
如果这个项目对您有帮助,欢迎给仓库点个star⭐️。如有任何问题或建议,也欢迎在评论区留言交流。