1. 论文背景与动机
《Deep Residual Learning for Image Recognition》是由何恺明(Kaiming He)、张翔宇(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jian Sun)于2015年提出的开创性论文,并于2016年6月在计算机视觉与模式识别会议(CVPR)上正式发表。这篇论文提出了残差学习框架,解决了深度神经网络训练中的退化问题,并在2015年的ImageNet和COCO竞赛中获得了多项冠军。
1.1 深度网络的优势
深度卷积神经网络在图像分类等视觉任务中取得了一系列突破性进展。深度网络的一个关键优势在于它能够自然地集成低/中/高级特征,并以端到端的多层方式整合分类器。网络的”深度”直接影响特征的丰富程度,通过增加堆叠层数可以提取更加复杂和抽象的特征表示。
研究证据表明,网络深度对性能至关重要。在ImageNet等具有挑战性的数据集上,领先的结果都采用了”非常深”的模型,深度从16层到30层不等。除了图像分类外,许多其他复杂的视觉识别任务,如目标检测、语义分割等,也从非常深的模型中获益匪浅。
深度网络的另一个优势是其表达能力随深度呈指数级增长,这使得它能够学习更加复杂的函数映射,捕捉数据中更细微的模式和特征。理论上,更深的网络应该至少能够达到与浅层网络相同的性能,因为浅层网络的解空间是深层网络解空间的子集。
1.2 深度网络的退化问题
随着神经网络层数的增加,研究人员发现了一个反直觉的现象:网络性能不升反降。论文将这种现象称为”退化问题”(degradation problem)。
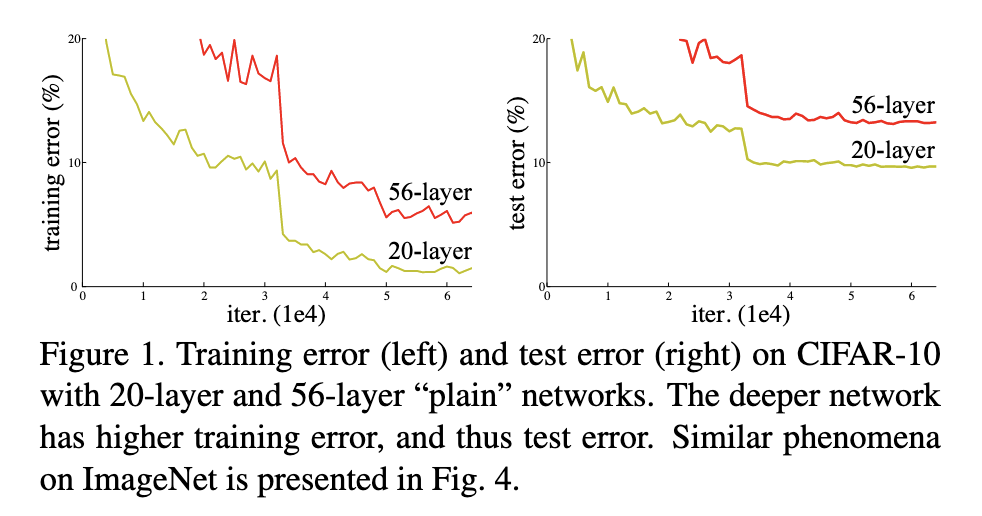
上图展示了56层网络的训练误差反而高于20层网络,这与我们期望的”更深的网络应该至少不比浅层网络差”的直觉相悖。
论文中明确指出,这种退化现象不是由过拟合引起的。如果是过拟合,我们会看到训练误差降低而测试误差增加,但实际上训练误差和测试误差都在增加。
1.3 研究动机
论文的核心动机是:如何构建更深的网络同时避免退化问题?
1.3.1 传统解决方法及其局限性
在深度网络训练中,最初面临的主要障碍是梯度消失/爆炸问题,这会阻碍网络从一开始就收敛。然而,这个问题已经在很大程度上通过以下方法得到解决:
- 归一化初始化:如He初始化、Xavier初始化等方法,使网络在初始阶段保持合理的梯度范围
- 中间归一化层:如批量归一化(Batch Normalization),确保前向传播的信号具有非零方差
这些方法使得包含数十层的网络能够开始通过随机梯度下降(SGD)和反向传播进行收敛。
然而,当更深的网络能够开始收敛时,退化问题就显现出来:随着网络深度增加,准确率先是饱和,然后迅速下降。这种现象在CIFAR-10和ImageNet等数据集上都有观察到。
从理论上讲,存在一个简单的解决方案:如果将浅层网络的权重复制到深层网络中,并将额外层设置为恒等映射,那么深层网络应该至少能够获得与浅层网络相同的性能。这个构造性解决方案的存在表明,深层网络的解空间包含了浅层网络的解空间。
然而,实验表明,当前的优化方法(如SGD)难以找到这样的解,或者至少难以在合理的时间内找到。论文推测,深层普通网络可能具有指数级低的收敛速率,这影响了训练误差的降低。这表明深度增加带来的不是表达能力问题,而是优化难度问题。
1.3.2 残差学习的核心假设
基于对退化问题的深入思考,何恺明等人提出了一个关键假设:直接拟合期望的底层映射比拟合残差映射更加困难。
具体来说,不再直接学习期望的底层映射函数$H(x)$,而是学习残差映射$F(x) = H(x) - x$,这样原始的映射可以重写为$H(x) = F(x) + x$,其中$x$是恒等映射。
这一假设基于以下观察:
- 如果最优映射接近于恒等映射,那么学习残差(与恒等映射的偏差)比从头学习整个映射更容易
- 在极端情况下,如果恒等映射是最优的,只需将残差推向零即可,这比通过一堆非线性层来拟合恒等映射要容易得多
论文通过实验证明,学习到的残差函数通常具有较小的响应,这表明恒等映射确实提供了合理的预处理,使优化变得更加容易。
2. 残差学习框架
2.1 核心思想
残差学习的核心思想是:与其直接学习期望的底层映射函数$H(x)$,不如学习残差映射$F(x) = H(x) - x$。这样原始的映射可以重写为$H(x) = F(x) + x$,其中$x$是恒等映射(identity mapping)。
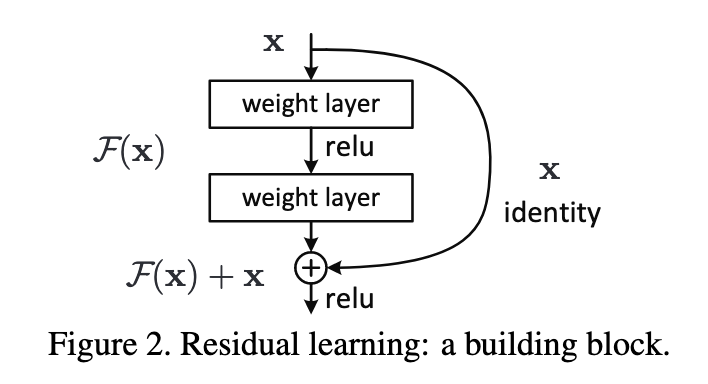
2.2 残差块结构
残差块是ResNet的基本构建单元,包含:
2.2.1 基本残差块
基本残差块包含两个3×3的卷积层,每层后跟批量归一化(Batch Normalization)和ReLU激活函数,最后通过跳跃连接(shortcut connection)将输入直接添加到输出。
残差块的数学表达式为:
$$y = F(x, {W_i}) + x$$
其中$F(x, {W_i})$表示残差映射,$x$是输入特征。
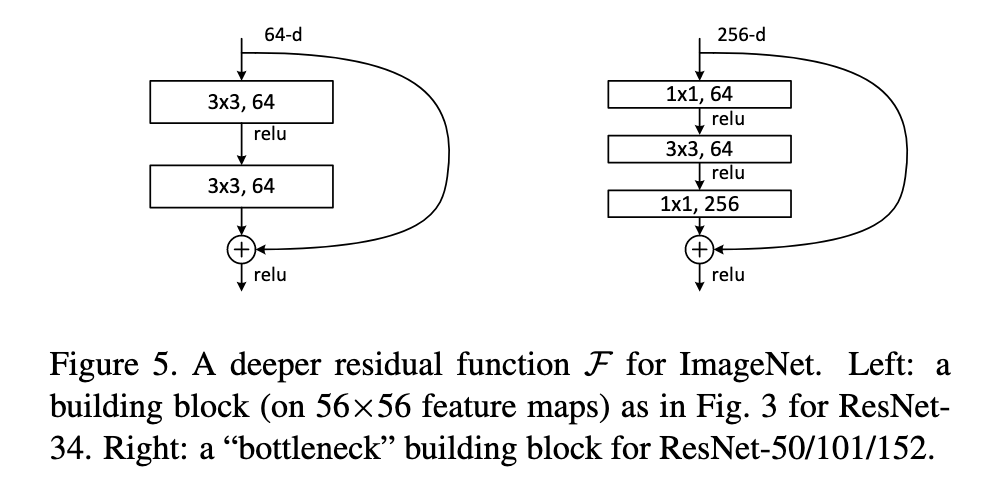
2.2.2 瓶颈残差块
为了提高计算效率,更深的ResNet(如ResNet-50/101/152)使用了瓶颈设计:
- 1×1卷积降维
- 3×3卷积处理
- 1×1卷积升维
这种设计大大减少了参数量和计算复杂度,同时保持了性能。
2.3 跳跃连接的类型
论文中讨论了两种类型的跳跃连接:
- 恒等跳跃连接:当输入和输出维度相同时,直接使用$y = F(x) + x$
- 投影跳跃连接:当维度不匹配时,使用1×1卷积进行线性投影:$y = F(x) + W_s x$
实验表明,只在维度变化时使用投影连接是一个好的折中方案。
上图展示了不同类型跳跃连接的性能对比。A表示所有跳跃连接都使用恒等映射,B表示维度增加时使用投影连接,C表示所有跳跃连接都使用投影连接。
3. 网络架构
3.1 整体架构
ResNet的整体架构如下:
- 7×7卷积层,64个滤波器,步长为2
- 3×3最大池化层,步长为2
- 多个残差块组成的阶段(stage)
- 全局平均池化层
- 全连接层和softmax分类器
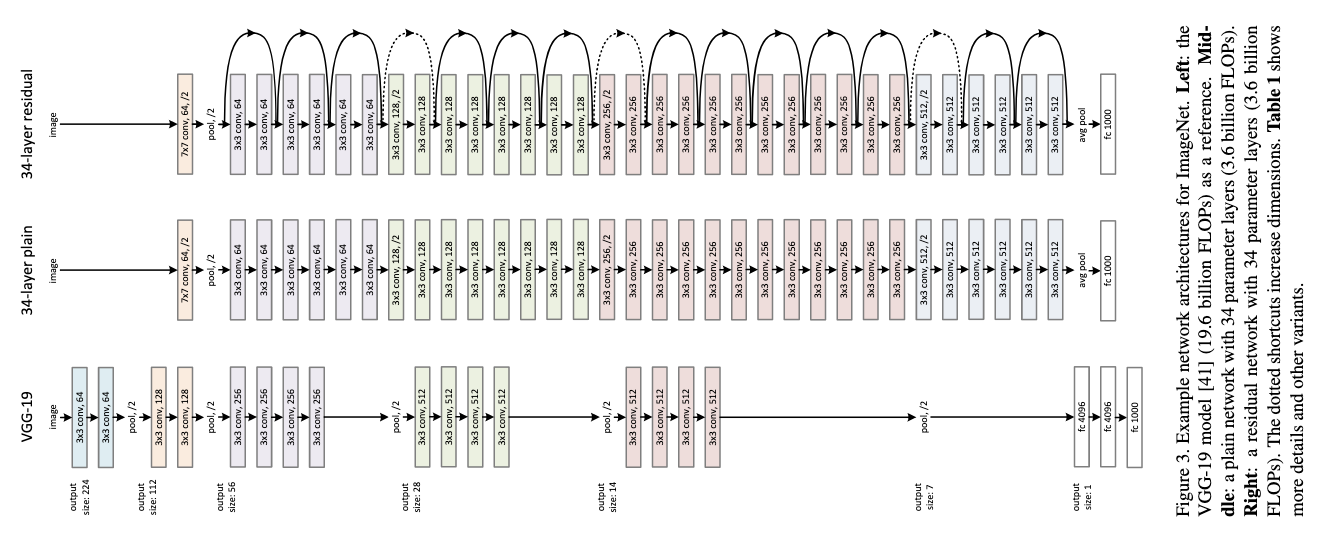
3.2 不同深度的ResNet变体
论文提出了多种不同深度的ResNet变体:
| 模型 | 层数 | 残差块类型 | 参数量 |
|---|---|---|---|
| ResNet-18 | 18 | 基本块 | 11.7M |
| ResNet-34 | 34 | 基本块 | 21.8M |
| ResNet-50 | 50 | 瓶颈块 | 25.6M |
| ResNet-101 | 101 | 瓶颈块 | 44.5M |
| ResNet-152 | 152 | 瓶颈块 | 60.2M |
下图展示了不同深度ResNet变体的详细架构设计:
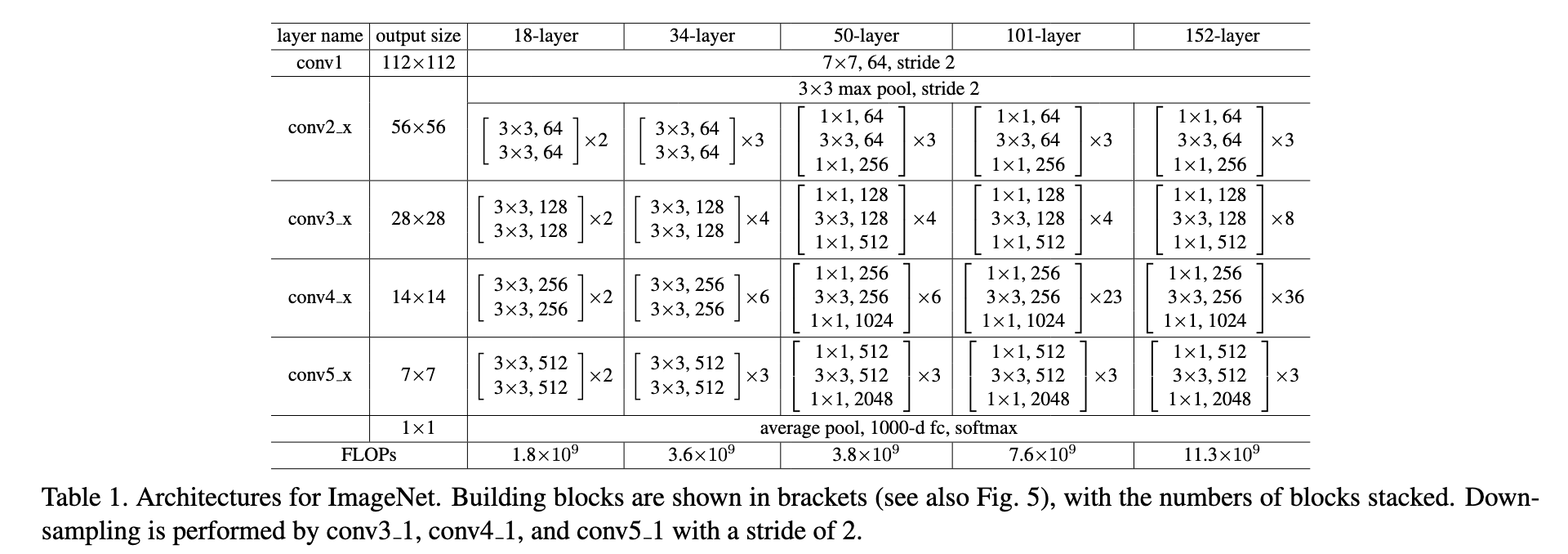
每个阶段的残差块数量和通道数如下:
1 | ResNet-18: [2, 2, 2, 2] |
4. 实验结果与分析
4.1 ImageNet分类结果
ResNet在ImageNet数据集上取得了显著的性能提升:
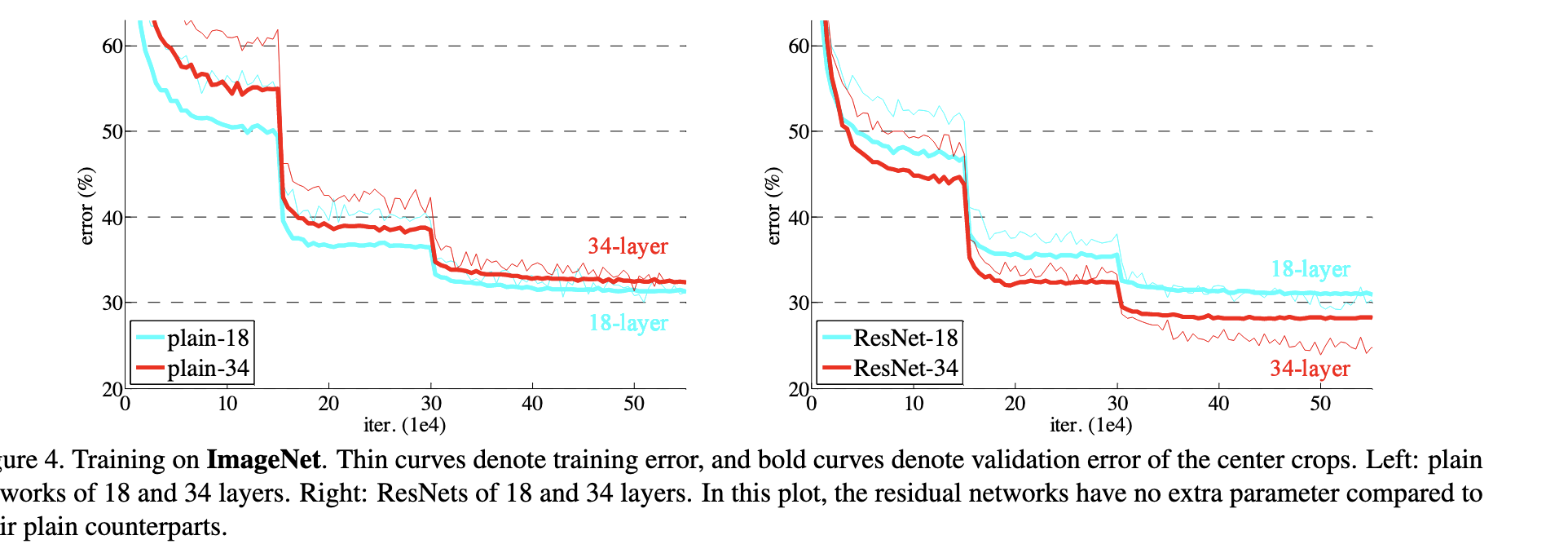
上图展示了普通网络与残差网络在训练过程中的误差曲线对比。可以看到,随着深度增加,普通网络的训练误差和测试误差都上升,而残差网络则能够持续降低误差。
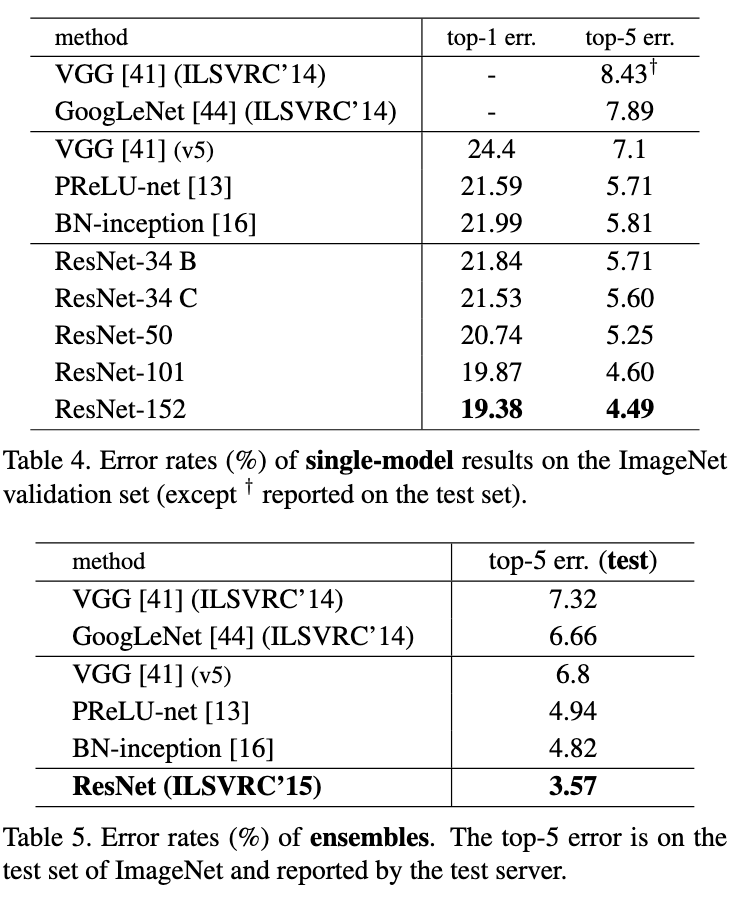
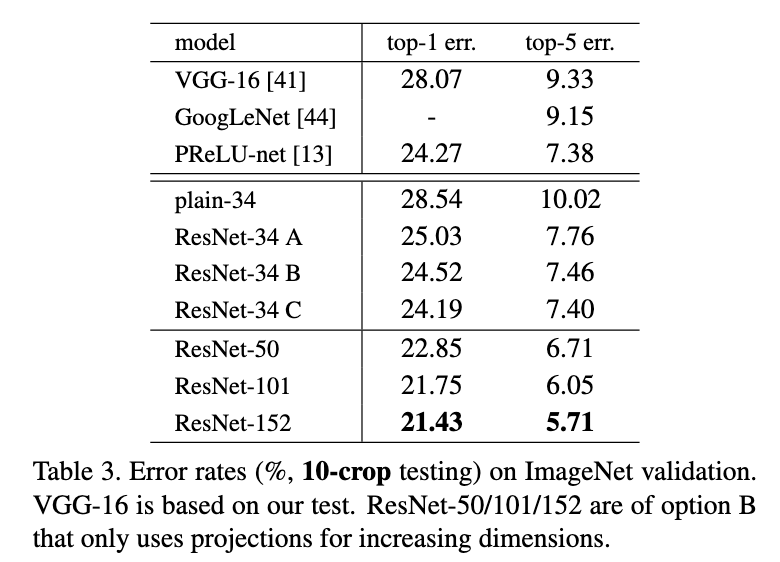
ResNet-152达到了4.49%的top-5错误率,比之前的最佳结果提升了约50%。更重要的是,实验证明了增加网络深度确实可以提高性能,这与之前的观察相反。
4.2 CIFAR-10实验
在CIFAR-10数据集上,作者构建了深度从20层到1202层的网络:
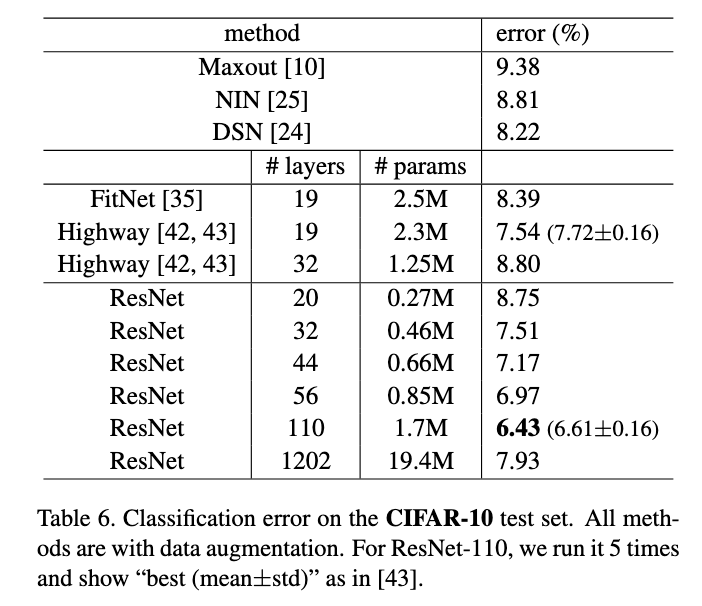
实验表明:
- 残差网络可以轻松训练超过100层的网络
- 深度增加确实提高了性能
- 过深的网络(如1202层)可能会过拟合
4.3 目标检测结果
在COCO目标检测竞赛中,基于ResNet的Faster R-CNN取得了显著提升:
- 28.2% mAP@[0.5, 0.95](比VGG-16高6.0%)
- 51.9% mAP@0.5(比VGG-16高6.9%)
这证明了ResNet作为骨干网络的通用性。
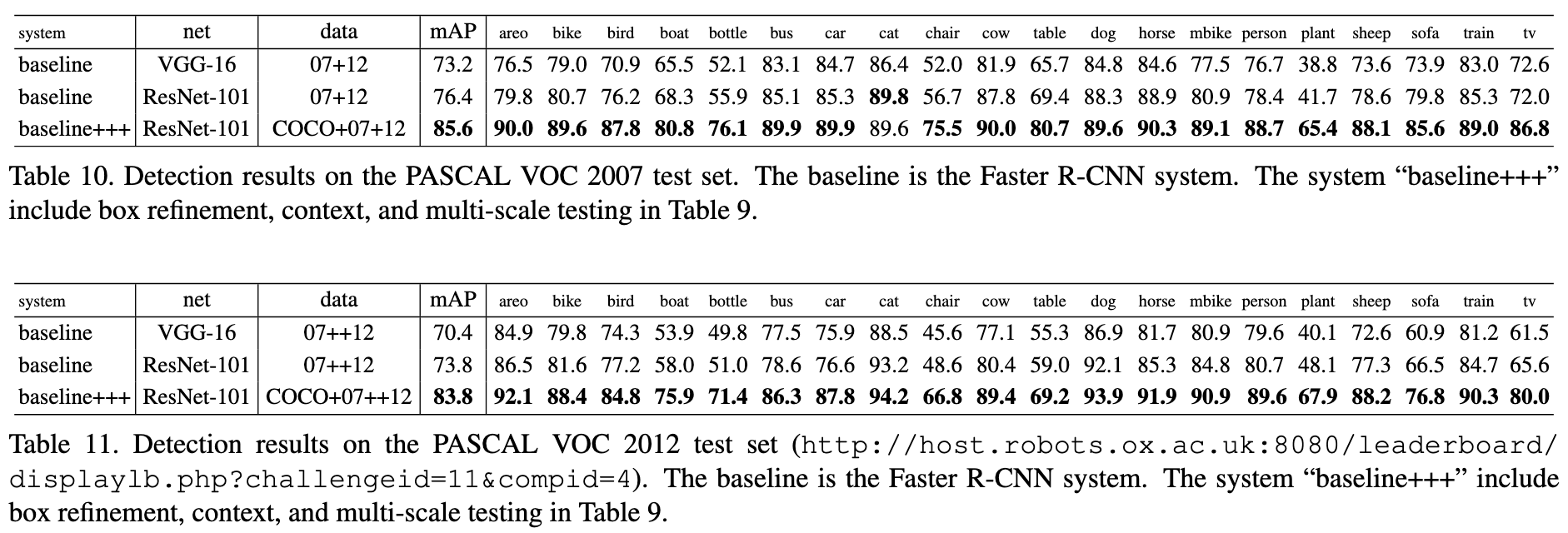
上图展示了ResNet在COCO目标检测任务上的性能,与其他网络架构相比,ResNet显著提升了检测精度。
5. 为什么残差连接有效?
5.1 论文中的实验证据
原论文主要通过实验证明了残差连接的有效性。以下是论文中提供的几点关键证据:
5.1.1 层响应分析
论文对CIFAR-10上训练的网络进行了层响应分析,测量了每个3×3层输出的标准差(在批量归一化后、非线性激活前)。结果显示:
- 残差网络的响应通常比对应的普通网络小
- 更深的残差网络(如ResNet-110)具有比浅层残差网络(如ResNet-20)更小的响应幅度
- 当层数增加时,残差网络中的单个层对信号的修改程度变小
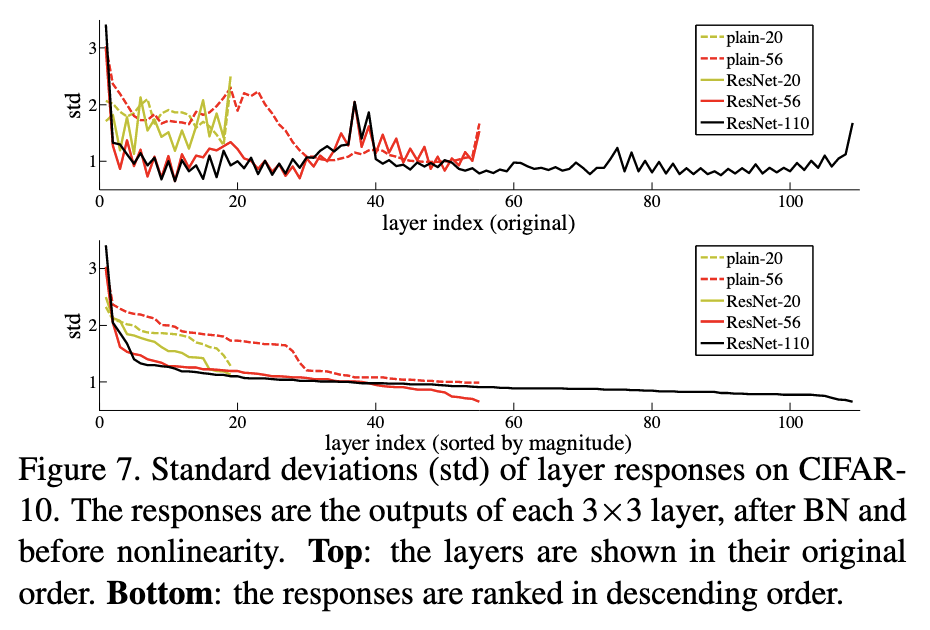
上图展示了残差网络中各层响应的标准差分布,可以看到残差函数的输出通常具有较小的幅度,这支持了论文的基本动机:残差函数可能更接近于零,比非残差函数更容易优化。
这些观察支持了论文的基本动机:残差函数可能更接近于零,比非残差函数更容易优化。
5.1.2 优化效果对比
论文通过对比实验证明,残差网络比普通网络更容易优化:
- 在ImageNet上,34层残差网络的训练误差显著低于34层普通网络
- 在CIFAR-10上,110层残差网络可以成功收敛,而对应的普通网络无法收敛(训练误差高于60%)
- 残差网络能够轻松训练超过100层甚至1000层的网络,而普通网络在深度增加时训练变得极其困难
5.1.3 恒等映射的重要性
论文通过实验强调了恒等映射(而非一般的跳跃连接)的重要性:
- 对于瓶颈结构,使用恒等跳跃连接比投影跳跃连接更高效,参数更少
- 当维度需要增加时,使用零填充的恒等映射几乎与投影跳跃连接性能相当,但参数更少
5.2 扩展思考:理论解释
以下内容是对ResNet工作原理的扩展思考,不完全来自原论文,而是结合后续研究对残差网络的理论分析。
5.2.1 梯度流分析
残差连接的一个关键优势是改善了梯度流。在反向传播过程中,梯度可以通过跳跃连接直接流向较浅层,缓解了梯度消失问题。
传统网络的梯度传播
在传统的前馈神经网络中,假设网络有$L$层,第$l$层的输出为$x_l$,权重为$W_l$,则前向传播可表示为:
$$x_{l+1} = H_l(x_l, W_l)$$
其中$H_l$是第$l$层的非线性变换。在反向传播中,损失函数$\mathcal{L}$对第$l$层输入$x_l$的梯度为:
$$\frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \frac{\partial x_{l+1}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \frac{\partial H_l(x_l, W_l)}{\partial x_l}$$
当网络很深时,连乘项$\prod_{i=l}^{L-1} \frac{\partial H_i(x_i, W_i)}{\partial x_i}$可能会变得非常小(梯度消失)或非常大(梯度爆炸),尤其是当$\frac{\partial H_i(x_i, W_i)}{\partial x_i}$的范数小于1时,梯度会随着层数的增加呈指数衰减。
残差网络的梯度传播
在残差网络中,第$l$层的前向传播为:
$$x_{l+1} = x_l + F_l(x_l, W_l)$$
其中$F_l$是残差函数。对应的反向传播梯度为:
$$\frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \frac{\partial x_{l+1}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \left( \frac{\partial F_l(x_l, W_l)}{\partial x_l} + 1 \right)$$
展开这个递推关系,我们可以得到:
$$\frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \left( \prod_{i=l}^{L-1} \frac{\partial F_i(x_i, W_i)}{\partial x_i} + \sum_{i=l}^{L-1} \prod_{j=l}^{i-1} \frac{\partial F_j(x_j, W_j)}{\partial x_j} + 1 \right)$$
这个表达式表明,梯度可以通过多条路径传播回较浅层:
- 通过所有残差块的连乘项
- 通过部分残差块的连乘项
- 直接通过恒等映射(”+1”项)
即使所有$\frac{\partial F_i(x_i, W_i)}{\partial x_i}$都接近零,梯度仍然可以通过恒等映射传播回去,这有效缓解了梯度消失问题。
5.2.2 信息流视角
从信息流的角度看,残差连接提供了一条捷径,使信息可以在网络中更自由地流动:
- 前向传播时,输入信息可以直接传递到更深层
- 反向传播时,梯度可以更容易地流回浅层
5.2.3 优化难度降低
残差学习将优化目标从拟合复杂的非线性映射转变为拟合残差,这在数学上更容易优化:
- 如果恒等映射是最优解,网络只需将残差部分的权重推向零
- 如果需要复杂映射,残差部分可以学习必要的变换
6. 总结与思考
通过对ResNet论文的深入解读,我们可以看到残差学习是如何优雅地解决深度神经网络的退化问题,使得构建和训练超深网络成为可能。ResNet的成功不仅体现在其卓越的性能上,更在于它所提出的残差学习这一基本思想,这一思想已经成为现代深度学习架构设计的基石。
从ResNet发表至今,深度学习领域已经涌现出许多基于残差连接的改进和变体,如DenseNet、ResNeXt等。这些网络在不同任务上都取得了显著的成功,进一步证明了残差学习的普适性和有效性。
作为计算机视觉领域的里程碑工作,ResNet不仅解决了一个具体的技术问题,更为深度学习的发展指明了方向。它告诉我们,有时候解决复杂问题的关键不在于设计更复杂的模型,而在于找到一种更简单、更优雅的方式来重新定义问题本身。
如果你对ResNet或其他深度学习架构有任何想法或疑问,欢迎在评论区留言讨论。
延伸阅读:如果你对ResNet的代码实现感兴趣,可以阅读我的后续文章《深度残差网络(ResNet)代码实现详解:PyTorch复现CIFAR-10图像分类》,其中详细介绍了如何使用PyTorch框架复现ResNet模型,并在CIFAR-10数据集上进行训练和评估。
参考文献
[1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770-778.
[2] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Identity Mappings in Deep Residual Networks. In European Conference on Computer Vision (ECCV), pp. 630-645.
[3] Veit, A., Wilber, M., & Belongie, S. (2016). Residual Networks Behave Like Ensembles of Relatively Shallow Networks. In Advances in Neural Information Processing Systems (NeurIPS), pp. 550-558.