1. 卷积神经网络的起源与发展
卷积神经网络(Convolutional Neural Network, CNN)是深度学习领域中最具代表性的神经网络架构之一,特别在计算机视觉任务中取得了巨大成功。自2012年AlexNet在ImageNet挑战赛上的突破性胜利以来,CNN已经彻底改变了计算机视觉领域,从图像分类、目标检测到语义分割,CNN在各种视觉任务上的表现已经接近或超过人类水平,推动了自动驾驶、医学影像分析、人脸识别等众多应用的快速发展。
本文旨在提供一个全面而深入的CNN发展综述,不仅介绍各个经典模型的技术细节,更重要的是分析每个模型产生的历史背景、试图解决的关键问题以及对后续研究的影响。通过系统回顾CNN的发展历程,从其起源到现代各种改进架构,我们将详细分析每个里程碑式模型的创新点、结构特点以及数学原理。
文章组织如下:第一部分介绍CNN的起源和早期发展;第二部分详细解析CNN的基本组件和工作原理;第三部分系统回顾经典CNN架构(LeNet-5、AlexNet、VGG、GoogLeNet和ResNet);第四部分探讨现代CNN架构(DenseNet、MobileNet和EfficientNet等)以及最新发展趋势;最后总结CNN的应用、挑战和未来发展方向。
通过这一系统性的回顾,读者将能够理解CNN架构设计的演进逻辑,把握深度学习在计算机视觉领域的发展脉络,为进一步研究和应用提供坚实基础。理解CNN的发展历程和设计原理,对于把握深度学习技术的过去、现在和未来具有重要意义。
1.1 神经网络早期发展
在CNN正式诞生之前,人工神经网络已经有了数十年的发展历史。1943年,McCulloch和Pitts提出了第一个数学模型来描述神经元的工作方式。1958年,Rosenblatt发明了感知机(Perceptron),这是第一个能够学习的神经网络模型。然而,单层感知机的局限性在1969年被Minsky和Papert指出,导致神经网络研究一度陷入低谷。
直到1986年,Rumelhart、Hinton和Williams提出了反向传播算法(Backpropagation),为训练多层神经网络提供了有效方法,神经网络研究才重新活跃起来。但是,传统的全连接神经网络在处理图像等高维数据时面临参数爆炸和计算效率低下的问题。
1.2 卷积神经网络的灵感来源
卷积神经网络的设计灵感来源于生物学中的视觉皮层结构。1959年,Hubel和Wiesel通过研究猫的视觉皮层发现,视觉神经元对特定区域的视觉刺激有反应,这一区域被称为感受野(receptive field)。不同神经元负责不同位置的感受野,共同构成了完整的视觉感知。
这一发现启发了神经网络研究者设计具有局部连接和权重共享特性的神经网络结构,最终导致了卷积神经网络的诞生。
2. CNN的基本组件与原理
在深入探讨各种CNN架构之前,我们需要理解CNN的基本组件和工作原理。CNN的设计灵感来源于生物视觉系统,通过局部连接和权重共享的特性,能够有效地处理具有网格状拓扑结构的数据,如图像。
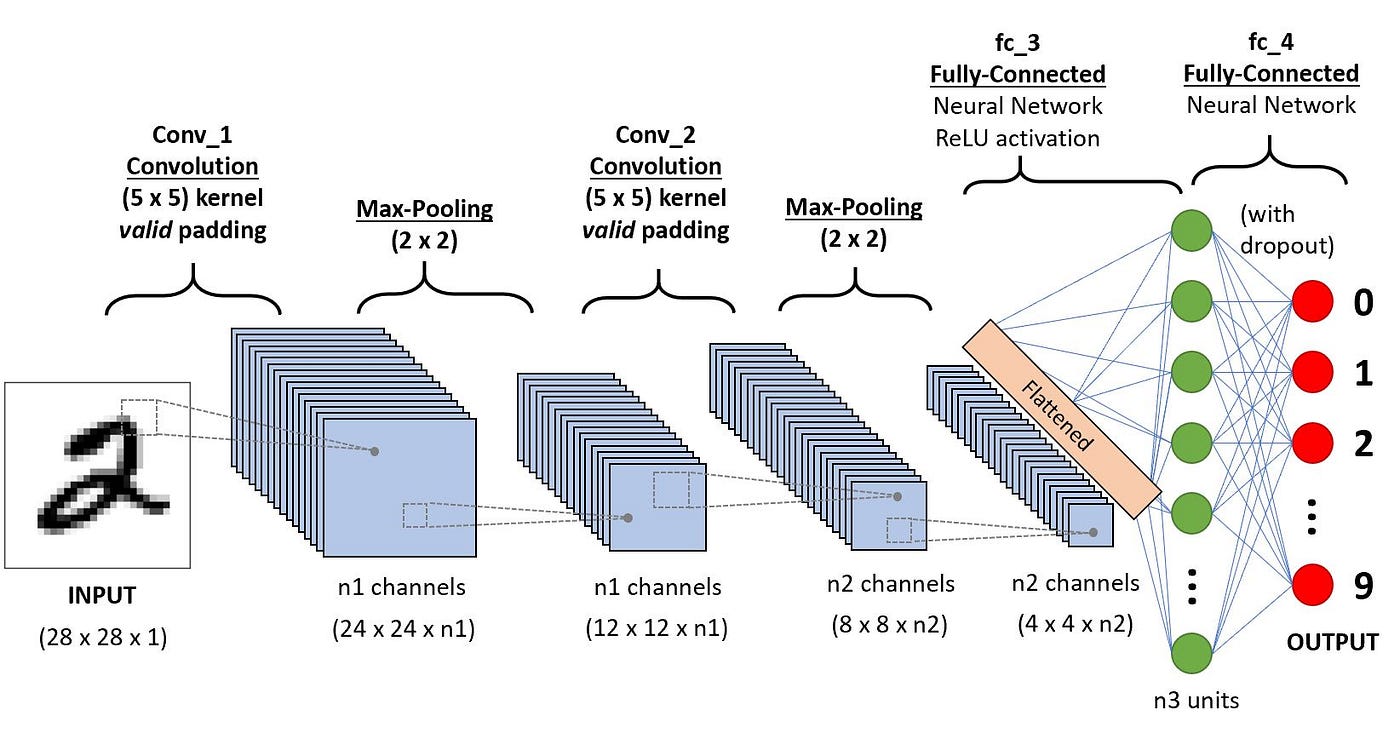
2.1 卷积层(Convolutional Layer)
卷积层是CNN的核心组件,负责提取输入数据的特征。卷积操作通过一个可学习的卷积核(kernel)或过滤器(filter)在输入数据上滑动,计算卷积核与输入数据对应区域的点积,生成特征图(feature map)。
2.1.1 卷积操作的数学表示
数学上,二维卷积操作可以表示为:
$$(I * K)(i, j) = \sum_m \sum_n I(i+m, j+n) \cdot K(m, n)$$
其中$I$是输入图像,$K$是卷积核,$(i,j)$是输出特征图的坐标。
对于多通道输入(如RGB图像)和多卷积核的情况,卷积操作可以扩展为:
$$z_{i,j,k} = \sum_{c=1}^{C_{in}} \sum_{m=0}^{F-1} \sum_{n=0}^{F-1} x_{i+m,j+n,c} \cdot w_{m,n,c,k} + b_k$$
其中:
- $z_{i,j,k}$ 是第$k$个输出特征图在位置$(i,j)$的值
- $x_{i,j,c}$ 是输入在位置$(i,j)$的第$c$个通道的值
- $w_{m,n,c,k}$ 是第$k$个卷积核的权重,连接输入通道$c$和位置$(m,n)$
- $b_k$ 是第$k$个卷积核的偏置
- $C_{in}$ 是输入通道数
- $F$ 是卷积核大小
2.1.2 卷积层输出大小计算
卷积层的输出特征图大小可以通过以下公式计算:
$$O_h = \lfloor \frac{I_h + 2P - F}{S} + 1 \rfloor$$
$$O_w = \lfloor \frac{I_w + 2P - F}{S} + 1 \rfloor$$
其中:
- $O_h$和$O_w$分别是输出特征图的高度和宽度
- $I_h$和$I_w$分别是输入特征图的高度和宽度
- $F$是卷积核大小(假设正方形卷积核)
- $P$是填充大小(padding)
- $S$是步长(stride)
- $\lfloor \cdot \rfloor$表示向下取整操作
例如,对于一个224×224的输入图像,使用7×7的卷积核,步长为2,填充为3,输出特征图大小为:
$$O_h = O_w = \lfloor \frac{224 + 2 \times 3 - 7}{2} + 1 \rfloor = \lfloor \frac{223}{2} + 1 \rfloor = \lfloor 112.5 \rfloor = 112$$
2.1.3 填充和步长
填充(Padding)和步长(Stride)是卷积操作的两个重要参数:
填充(Padding):在输入特征图的边缘添加额外的像素(通常为0),以控制输出特征图的空间维度。常见的填充策略包括:
- 有效填充(Valid Padding):不添加填充,输出特征图尺寸减小
- 相同填充(Same Padding):添加适当的填充,使输出特征图与输入特征图具有相同的空间维度
- 全填充(Full Padding):添加足够的填充,使卷积核的每个元素至少与输入特征图的一个元素重叠一次
步长(Stride):卷积核在输入特征图上滑动的步长。较大的步长会减小输出特征图的空间维度,同时减少计算量。
2.1.4 卷积层的特点
卷积层的主要特点包括:
- 局部连接:每个神经元只与输入数据的一个局部区域相连,大大减少了参数数量。
- 权重共享:同一个卷积核在整个输入数据上共享权重,进一步减少参数数量,同时使网络具有平移不变性。
- 平移不变性:无论特征在输入中的位置如何,都能被相同的卷积核检测到。
- 层次化特征提取:浅层卷积层提取低级特征(如边缘、纹理),深层卷积层提取高级特征(如物体部件、完整物体)。
2.2 池化层(Pooling Layer)
池化层通常跟在卷积层之后,用于降低特征图的空间维度,减少参数数量和计算量,同时提高模型对输入变化的鲁棒性。
2.2.1 池化操作
常见的池化操作包括:
最大池化(Max Pooling):从输入的局部区域中选择最大值作为输出。最大池化保留了区域内最显著的特征,对于纹理和边缘等特征尤其有效。
平均池化(Average Pooling):计算输入局部区域的平均值作为输出。平均池化保留了区域内的整体特征,对于背景等平滑区域更为有效。
全局池化(Global Pooling):对整个特征图进行池化,通常用于网络的最后阶段,将特征图转换为固定长度的特征向量。
池化操作可以表示为:
$$y_{i,j} = \text{pool}(x_{i \cdot s:i \cdot s+k, j \cdot s:j \cdot s+k})$$
其中$\text{pool}$是池化函数(如max或average),$s$是步长,$k$是池化窗口大小。
2.2.2 池化层输出大小计算
池化层的输出特征图大小可以通过以下公式计算:
$$O_h = \lfloor \frac{I_h - F}{S} + 1 \rfloor$$
$$O_w = \lfloor \frac{I_w - F}{S} + 1 \rfloor$$
其中:
- $O_h$和$O_w$分别是输出特征图的高度和宽度
- $I_h$和$I_w$分别是输入特征图的高度和宽度
- $F$是池化窗口大小
- $S$是步长
例如,对于一个112×112的输入特征图,使用3×3的最大池化,步长为2,输出特征图大小为:
$$O_h = O_w = \lfloor \frac{112 - 3}{2} + 1 \rfloor = \lfloor \frac{109}{2} + 1 \rfloor = \lfloor 55.5 \rfloor = 55$$
2.2.3 池化层的作用
池化层在CNN中起到以下几个重要作用:
- 降维:减少特征图的空间维度,降低后续层的计算复杂度。
- 提取显著特征:通过选择区域内的最大值或平均值,保留最重要的特征信息。
- 增加感受野:间接增大了后续层对原始输入的感受野。
- 提高鲁棒性:对输入的微小变化不敏感,增强模型的平移不变性。
2.3 感受野(Receptive Field)
感受野是CNN中的一个重要概念,指的是输出特征图上的一个点对应输入图像上的区域大小。感受野决定了网络能够”看到”的上下文信息范围,对于许多视觉任务(如目标检测和语义分割)至关重要。
2.3.1 感受野计算
对于由多个卷积层和池化层组成的网络,第$l$层的感受野大小可以通过以下递推公式计算:
$$RF_l = RF_{l-1} + (k_l - 1) \times \prod_{i=1}^{l-1} s_i$$
其中:
- $RF_l$是第$l$层的感受野大小
- $k_l$是第$l$层的卷积核或池化窗口大小
- $s_i$是第$i$层的步长
对于第一层,$RF_1 = k_1$。
例如,考虑一个由两个3×3卷积层(步长为1)和一个2×2最大池化层(步长为2)组成的简单网络:
- 第一卷积层的感受野:$RF_1 = 3$
- 第二卷积层的感受野:$RF_2 = RF_1 + (k_2 - 1) \times s_1 = 3 + (3 - 1) \times 1 = 5$
- 池化层的感受野:$RF_3 = RF_2 + (k_3 - 1) \times s_1 \times s_2 = 5 + (2 - 1) \times 1 \times 1 = 6$
如果在池化层之后再添加一个3×3卷积层(步长为1),则其感受野为:
$RF_4 = RF_3 + (k_4 - 1) \times s_1 \times s_2 \times s_3 = 6 + (3 - 1) \times 1 \times 1 \times 2 = 10$
注意步长的累积效应:池化层的步长为2,使得后续层的感受野增长速度加倍。
2.3.2 感受野的重要性
感受野大小对CNN的性能有重要影响:
- 小感受野:适合捕获局部细节和纹理,但可能缺乏全局上下文信息。
- 大感受野:能够捕获更广泛的上下文信息,有助于理解整体场景和物体关系。
不同的视觉任务可能需要不同大小的感受野:
- 图像分类通常需要较大的感受野,以捕获整个物体的特征。
- 目标检测和语义分割需要平衡局部细节和全局上下文,通常采用多尺度特征融合的策略。
增大感受野的常用方法包括:
- 增加网络深度
- 使用更大的卷积核
- 使用空洞卷积(Dilated/Atrous Convolution)
- 使用池化层增加步长
2.3 激活函数(Activation Function)
激活函数为神经网络引入非线性,使网络能够学习更复杂的模式。如果没有激活函数,多层神经网络将等价于单层线性变换,无法学习复杂的特征表示。
2.3.1 常用激活函数
在CNN中常用的激活函数包括:
ReLU(Rectified Linear Unit):$f(x) = \max(0, x)$
- 优点:计算简单,缓解梯度消失问题,促进稀疏激活
- 缺点:存在”死亡ReLU”问题(神经元永久失活)
Leaky ReLU:$f(x) = \max(\alpha x, x)$,其中$\alpha$是一个小正数(如0.01)
- 优点:解决了”死亡ReLU”问题
- 缺点:引入了额外的超参数$\alpha$
Parametric ReLU (PReLU):$f(x) = \max(\alpha x, x)$,其中$\alpha$是可学习的参数
- 优点:自适应学习负半轴的斜率
- 缺点:增加了模型复杂度
ELU (Exponential Linear Unit):$f(x) = \begin{cases} x, & \text{if } x > 0 \ \alpha(e^x - 1), & \text{if } x \leq 0 \end{cases}$
- 优点:对负输入有非零输出,减轻了偏置偏移问题
- 缺点:计算复杂度高于ReLU
Sigmoid:$f(x) = \frac{1}{1 + e^{-x}}$
- 优点:输出范围在(0,1)之间,适合二分类问题
- 缺点:存在梯度消失问题,输出不以零为中心
Tanh:$f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$
- 优点:输出范围在(-1,1)之间,以零为中心
- 缺点:仍存在梯度消失问题
Swish:$f(x) = x \cdot \sigma(x)$,其中$\sigma(x)$是sigmoid函数
- 优点:平滑、非单调,在多种任务上表现优于ReLU
- 缺点:计算复杂度高于ReLU
在现代CNN中,ReLU及其变体(如Leaky ReLU、PReLU)因其计算简单且能有效缓解梯度消失问题,成为最常用的激活函数。近年来,Swish等新型激活函数在某些任务上表现出优于ReLU的性能,也逐渐得到应用。
2.4 全连接层(Fully Connected Layer)
全连接层通常位于CNN的末端,将前面层提取的特征映射到最终的输出类别。在全连接层中,每个神经元与前一层的所有神经元相连。
全连接层的计算可以表示为:
$$y = f(Wx + b)$$
其中$W$是权重矩阵,$x$是输入向量,$b$是偏置向量,$f$是激活函数。
全连接层在CNN中的主要作用是:
- 将卷积层和池化层提取的空间特征转换为分类所需的特征表示
- 学习特征之间的非线性组合
- 映射到最终的输出空间(如类别概率)
然而,全连接层也存在参数量大、容易过拟合的问题。在现代CNN架构中,全连接层常被全局平均池化(Global Average Pooling)等更高效的结构所替代。
2.5 批量归一化(Batch Normalization)
批量归一化是一种重要的正则化技术,通过标准化每一层的输入,加速网络训练并提高模型性能。批量归一化的计算过程包括:
- 计算批次内每个特征的均值:$\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i$
- 计算批次内每个特征的方差:$\sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2$
- 标准化:$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$
- 缩放和平移:$y_i = \gamma \hat{x}_i + \beta$
其中$\gamma$和$\beta$是可学习的参数,$\epsilon$是一个小常数,用于数值稳定性。
批量归一化的主要优点包括:
- 缓解内部协变量偏移(Internal Covariate Shift)问题
- 允许使用更高的学习率,加速训练
- 减少对初始化的敏感性
- 具有轻微的正则化效果
2.6 Dropout
Dropout是一种有效的正则化技术,在训练过程中随机”丢弃”一部分神经元,防止模型过拟合。数学上,Dropout可以表示为:
$$y = f(Wx) \odot m, \quad m_i \sim \text{Bernoulli}(p)$$
其中$\odot$表示元素乘积,$m$是一个二元掩码向量,每个元素以概率$p$独立地取值为1(保留)或0(丢弃)。
在测试阶段,所有神经元都参与计算,但输出需要乘以保留概率$p$进行缩放,或者等效地,在训练时将保留的激活值除以$p$。
Dropout的工作原理可以从以下几个角度理解:
- 集成学习:相当于训练了多个不同网络的集成,每次随机丢弃一部分神经元相当于训练了一个子网络
- 共适应性减少:防止神经元之间的强依赖关系,促使每个神经元学习更加鲁棒的特征
- 噪声注入:为训练过程引入噪声,增强模型的泛化能力
Dropout主要应用于全连接层,在卷积层中的效果相对有限,因为卷积层已经具有较强的参数共享和正则化特性。
2.7 CNN的前向传播和反向传播
2.7.1 前向传播
CNN的前向传播是指从输入到输出的计算过程。对于一个典型的CNN,前向传播包括以下步骤:
- 输入层接收原始图像数据
- 卷积层通过卷积操作提取特征
- 激活函数引入非线性
- 池化层降低特征图维度
- 重复上述步骤多次,形成深层特征表示
- 全连接层将特征映射到输出空间
- 输出层(通常是softmax函数)生成最终预测
2.7.2 反向传播
反向传播是CNN训练的核心算法,用于计算损失函数对网络参数的梯度,并更新参数。反向传播的基本步骤包括:
- 计算输出层的误差(预测值与真实值之间的差异)
- 从后向前,计算每一层的误差梯度
- 计算损失函数对每层参数的梯度
- 使用梯度下降或其他优化算法更新参数
对于卷积层,反向传播涉及到卷积操作的梯度计算,可以表示为另一个卷积操作。具体来说,如果前向传播是:
$$z = x * w$$
其中$*$表示卷积操作,$x$是输入,$w$是卷积核,$z$是输出。
则反向传播中,损失函数$L$对输入$x$的梯度为:
$$\frac{\partial L}{\partial x} = \frac{\partial L}{\partial z} * \text{rot180}(w)$$
其中$\text{rot180}(w)$表示将卷积核旋转180度。
损失函数对卷积核$w$的梯度为:
$$\frac{\partial L}{\partial w} = x * \frac{\partial L}{\partial z}$$
这里的卷积操作需要考虑适当的填充和步长。
通过反向传播算法,CNN能够自动学习从原始输入到目标输出的映射,无需手动设计特征提取器,这是CNN在计算机视觉任务中取得巨大成功的关键因素。
3. 经典CNN架构详解
接下来,我们将按时间顺序详细介绍CNN发展历程中的里程碑式架构,分析它们的创新点、网络结构和性能表现。
3.1 LeNet-5 (1998)
LeNet-5是由Yann LeCun等人在1998年提出的,是第一个成功应用于实际问题的卷积神经网络架构。它最初被设计用于手写数字识别,在当时的MNIST数据集上取得了显著的成功。
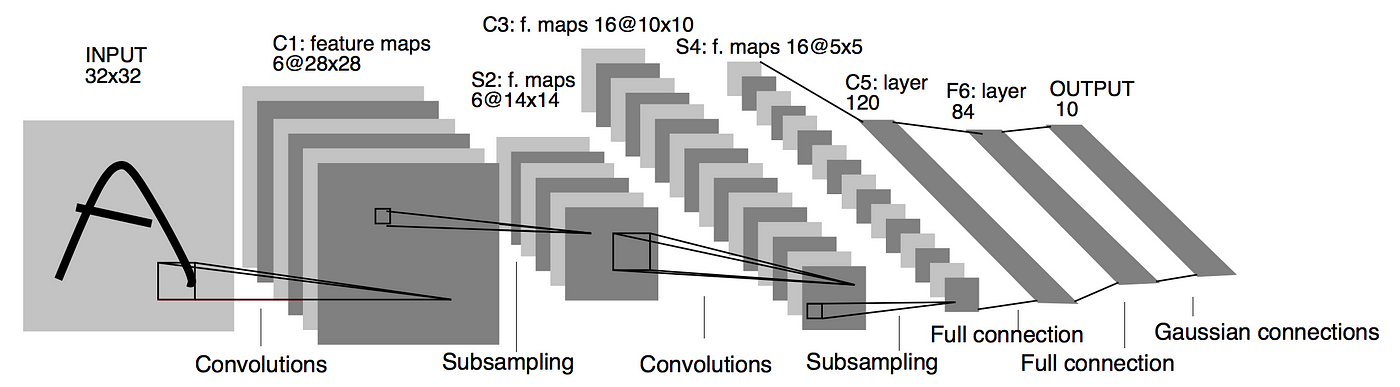
3.1.1 网络结构
LeNet-5包含7层(不包括输入层),其中有3个卷积层、2个池化层和2个全连接层:
- 输入层:32×32像素的灰度图像
- C1层(卷积层):使用6个5×5的卷积核,输出6个28×28的特征图
- S2层(池化层):2×2的平均池化,步长为2,输出6个14×14的特征图
- C3层(卷积层):使用16个5×5的卷积核,但采用了特殊的稀疏连接模式,输出16个10×10的特征图
- S4层(池化层):2×2的平均池化,步长为2,输出16个5×5的特征图
- C5层(卷积层):使用120个5×5的卷积核,输出120个1×1的特征图
- F6层(全连接层):84个神经元
- 输出层:10个神经元,对应10个数字类别
LeNet-5的一个特殊之处在于C3层的稀疏连接模式。不同于现代CNN中常见的全连接模式(每个卷积核与前一层的所有特征图相连),LeNet-5的C3层采用了一种特殊的连接方式,如下表所示:
| 特征图 | S2层的输入特征图 |
|---|---|
| 0 | 0, 1, 2 |
| 1 | 1, 2, 3 |
| 2 | 2, 3, 4 |
| 3 | 3, 4, 5 |
| 4 | 0, 4, 5 |
| 5 | 0, 1, 5 |
| 6 | 0, 1, 2, 3 |
| 7 | 1, 2, 3, 4 |
| 8 | 2, 3, 4, 5 |
| 9 | 0, 3, 4, 5 |
| 10 | 0, 1, 4, 5 |
| 11 | 0, 1, 2, 5 |
| 12 | 0, 1, 3, 4 |
| 13 | 1, 2, 4, 5 |
| 14 | 0, 2, 3, 5 |
| 15 | 0, 1, 2, 3, 4, 5 |
这种稀疏连接模式的设计目的是减少参数数量,同时强制不同的特征图学习不同的特征。
3.1.2 数学原理
LeNet-5中的卷积操作可以表示为:
$$x_j^l = f\left(\sum_{i \in M_j} x_i^{l-1} * k_{ij}^l + b_j^l\right)$$
其中:
- $x_j^l$ 是第$l$层的第$j$个特征图
- $M_j$ 是第$l-1$层中与第$l$层的第$j$个特征图相连的特征图集合
- $k_{ij}^l$ 是从第$l-1$层的第$i$个特征图到第$l$层的第$j$个特征图的卷积核
- $b_j^l$ 是第$l$层第$j$个特征图的偏置
- $f$ 是激活函数,LeNet-5使用的是sigmoid函数的变种:$f(x) = A \tanh(Sx)$,其中$A=1.7159$,$S=2/3$
LeNet-5的池化操作(称为”子采样”)可以表示为:
$$x_j^l = f\left(\beta_j^l \cdot \text{down}(x_j^{l-1}) + b_j^l\right)$$
其中:
- $\text{down}(\cdot)$ 是降采样操作,计算2×2区域内的平均值
- $\beta_j^l$ 和 $b_j^l$ 是可学习的参数
3.1.3 创新点与贡献
LeNet-5的主要创新点和贡献包括:
- 引入卷积操作:利用卷积操作自动提取特征,避免了手工设计特征的繁琐过程。
- 局部感受野:每个神经元只连接到输入的一个局部区域,大大减少了参数数量。
- 权重共享:同一特征图中的神经元共享相同的权重,进一步减少参数数量。
- 层次化特征提取:通过多层结构逐步提取从低级到高级的特征。
- 子采样层(池化层):通过降低分辨率增加位置不变性,同时减少计算量。
LeNet-5虽然在今天看来结构简单,但它包含了现代CNN的核心思想,为后续CNN的发展奠定了坚实的基础。然而,由于当时计算资源有限,以及缺乏有效的训练技术(如ReLU激活函数、Dropout正则化等),LeNet-5的应用范围主要局限于手写数字识别等简单任务。
直到2012年AlexNet的出现,CNN才真正在大规模视觉识别任务中展现出强大的潜力。AlexNet通过利用GPU计算能力和大规模数据集,成功解决了深度CNN训练中的关键挑战,开启了深度学习在计算机视觉领域的新纪元。
3.2 AlexNet (2012)
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出的深度卷积神经网络,它在2012年的ImageNet大规模视觉识别挑战赛(ILSVRC)中以显著优势获得冠军,将Top-5错误率从之前最好的26.2%降低到了15.3%,这一突破性成就标志着深度学习在计算机视觉领域的崛起,也被认为是深度学习复兴的开端。
3.2.1 问题背景
在AlexNet出现之前,计算机视觉领域主要依赖手工设计的特征提取器(如SIFT、HOG等)和浅层学习模型。这些方法在处理复杂、多变的自然图像时表现有限。同时,尽管深度神经网络理论上具有强大的表达能力,但实际应用面临几个关键挑战:
- 数据不足:训练深度网络需要大量标注数据
- 计算资源限制:深度网络的训练需要强大的计算能力
- 优化困难:深层网络容易出现梯度消失/爆炸问题
- 过拟合严重:参数众多的深度网络极易过拟合
AlexNet的出现正是为了解决这些问题。它利用ImageNet这一大规模数据集,结合GPU并行计算能力,并引入了ReLU激活函数和Dropout等技术,成功训练了一个8层的深度CNN,证明了深度学习在视觉识别任务上的巨大潜力。
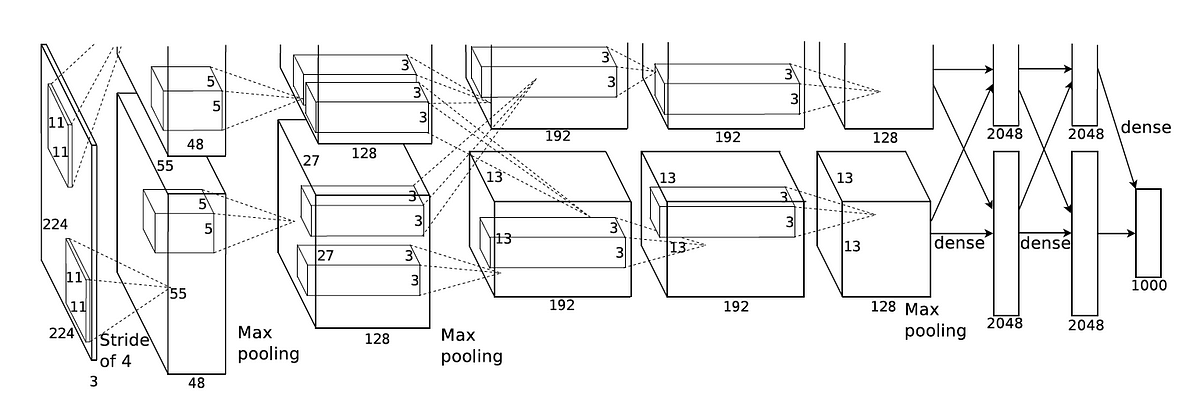
3.2.2 网络结构
AlexNet包含8层:5个卷积层和3个全连接层。由于当时GPU内存有限,网络被分成两部分,分别在两个GPU上运行。
- 输入层:224×224×3的RGB图像
- 第一卷积层:使用96个11×11的卷积核,步长为4,输出55×55×96的特征图,然后经过ReLU激活函数、局部响应归一化(LRN)和3×3的最大池化(步长为2)
- 第二卷积层:使用256个5×5的卷积核,步长为1,填充为2,输出27×27×256的特征图,然后经过ReLU激活函数、LRN和3×3的最大池化(步长为2)
- 第三卷积层:使用384个3×3的卷积核,步长为1,填充为1,输出13×13×384的特征图,然后经过ReLU激活函数
- 第四卷积层:使用384个3×3的卷积核,步长为1,填充为1,输出13×13×384的特征图,然后经过ReLU激活函数
- 第五卷积层:使用256个3×3的卷积核,步长为1,填充为1,输出13×13×256的特征图,然后经过ReLU激活函数和3×3的最大池化(步长为2)
- 全连接层1:4096个神经元,ReLU激活函数,Dropout(0.5)
- 全连接层2:4096个神经元,ReLU激活函数,Dropout(0.5)
- 全连接层3:1000个神经元,对应ImageNet的1000个类别,Softmax激活函数
AlexNet的总参数量约为6000万,这在当时是一个非常大的模型。
3.2.3 数学原理
AlexNet中引入了几个关键的数学组件:
ReLU激活函数:
$$f(x) = \max(0, x)$$相比于传统的sigmoid或tanh激活函数,ReLU计算更简单,且能有效缓解梯度消失问题,加速训练过程。
局部响应归一化(LRN):
$$b_{x,y}^i = a_{x,y}^i / \left(k + \alpha \sum_{j=\max(0, i-n/2)}^{\min(N-1, i+n/2)} (a_{x,y}^j)^2\right)^\beta$$其中:
- $a_{x,y}^i$ 是位置 $(x,y)$ 处第 $i$ 个卷积核的激活值
- $b_{x,y}^i$ 是归一化后的响应
- $N$ 是该层的卷积核总数
- $k, \alpha, \beta, n$ 是超参数,在AlexNet中设置为 $k=2, \alpha=10^{-4}, \beta=0.75, n=5$
LRN模拟了生物神经系统中的侧抑制(lateral inhibition)机制,使得响应较大的神经元抑制周围神经元的活动,增强了模型的泛化能力。
Dropout正则化:
在训练过程中,以概率 $p$ (AlexNet中为0.5)随机将神经元的输出设为0,测试时所有神经元都参与计算,但输出要乘以 $p$ 进行缩放。这相当于训练了多个不同网络的集成,有效减少过拟合。数据增强:
通过随机裁剪、水平翻转、颜色和光照变换等方式人为增加训练样本的多样性,提高模型的泛化能力。
3.2.4 创新点与贡献
AlexNet的主要创新点和贡献包括:
更深的网络结构:相比LeNet-5,AlexNet具有更多的层和更大的模型容量,能够学习更复杂的特征表示。
ReLU激活函数:首次在大型CNN中成功应用ReLU激活函数,解决了深度网络训练中的梯度消失问题,使得深度网络的训练变得更加高效。
Dropout正则化:引入Dropout技术有效减少过拟合,提高模型泛化能力。
局部响应归一化(LRN):通过模拟生物神经系统的侧抑制机制,增强了模型的泛化能力。
数据增强:通过各种图像变换技术人为增加训练数据的多样性,提高模型的鲁棒性。
GPU加速:首次利用GPU进行大规模CNN训练,证明了GPU在深度学习中的重要性。
大规模数据集训练:在包含120万张图像的ImageNet数据集上训练,证明了大数据对深度学习的重要性。
AlexNet的成功不仅在于其技术创新,更重要的是它证明了深度学习在计算机视觉领域的巨大潜力,引发了学术界和工业界对深度学习的广泛关注,推动了深度学习的快速发展。在AlexNet之后,CNN架构的研究进入了一个百花齐放的时代,各种更深、更复杂的网络结构相继被提出。
AlexNet的成功证明了增加网络深度可以提高模型性能,但其不规则的网络结构设计使得进一步扩展变得困难。研究者们开始思考:如何设计更加规整、更易扩展的深度网络架构?VGG网络通过采用统一的小卷积核和简洁的网络结构,为这一问题提供了优雅的解决方案。
3.3 VGG (2014)
VGG网络是由牛津大学Visual Geometry Group的Karen Simonyan和Andrew Zisserman在2014年提出的,在2014年的ILSVRC比赛中获得了分类任务第二名和定位任务第一名。VGG网络以其简洁统一的架构设计和出色的性能而闻名,成为了深度学习领域的经典模型之一。
3.3.1 问题背景
AlexNet的成功证明了增加网络深度可以提高模型性能,但如何设计更深的网络架构成为了研究者面临的新挑战。主要问题包括:
- 网络设计复杂性:AlexNet使用了不同大小的卷积核和复杂的分组卷积,设计较为繁琐
- 参数效率:如何在增加深度的同时控制参数数量
- 特征表达能力:如何通过网络设计增强模型的特征学习能力
- 训练稳定性:更深的网络往往更难训练,容易出现梯度问题
VGG网络通过极简主义的设计理念解决了这些问题,它用多个小卷积核堆叠替代大卷积核,创建了一种规整、易于扩展的网络架构模板,为后续更深网络的设计提供了范式。
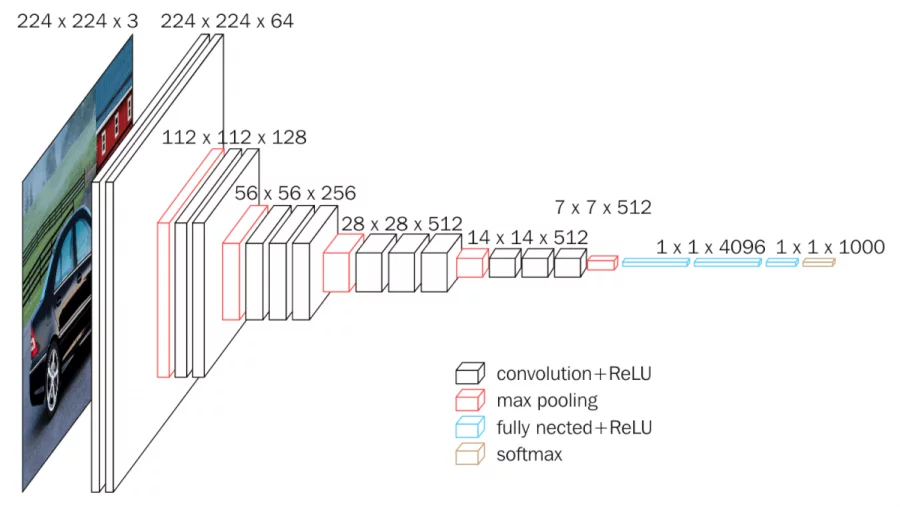
3.3.2 网络结构
VGG网络有多个变体,最常用的是VGG-16和VGG-19,分别包含16层和19层(只计算带权重的层)。以VGG-16为例,其结构如下:
- 输入层:224×224×3的RGB图像
- 卷积块1:
- 两个3×3卷积层,每层64个卷积核,ReLU激活
- 2×2最大池化,步长为2
- 卷积块2:
- 两个3×3卷积层,每层128个卷积核,ReLU激活
- 2×2最大池化,步长为2
- 卷积块3:
- 三个3×3卷积层,每层256个卷积核,ReLU激活
- 2×2最大池化,步长为2
- 卷积块4:
- 三个3×3卷积层,每层512个卷积核,ReLU激活
- 2×2最大池化,步长为2
- 卷积块5:
- 三个3×3卷积层,每层512个卷积核,ReLU激活
- 2×2最大池化,步长为2
- 全连接层1:4096个神经元,ReLU激活,Dropout(0.5)
- 全连接层2:4096个神经元,ReLU激活,Dropout(0.5)
- 全连接层3:1000个神经元,Softmax激活
VGG-19比VGG-16多了3个卷积层,分别在卷积块3、4和5中各增加一个3×3卷积层。
VGG网络的一个显著特点是使用了非常统一的结构:所有卷积层都使用3×3的小卷积核,步长为1,填充为1;所有池化层都是2×2的最大池化,步长为2。这种设计使得网络结构非常规整,易于理解和实现。
VGG-16的总参数量约为1.38亿,VGG-19约为1.44亿,远超AlexNet的6000万参数。
3.3.3 数学原理
VGG网络的核心创新在于使用多个小卷积核堆叠代替大卷积核。例如,两个连续的3×3卷积层的感受野等价于一个5×5的卷积层,三个连续的3×3卷积层等价于一个7×7的卷积层,但参数数量大大减少:
- 一个7×7卷积层的参数数量:$7 \times 7 \times C_{in} \times C_{out} = 49 \times C_{in} \times C_{out}$
- 三个3×3卷积层的参数数量:$3 \times (3 \times 3 \times C_{in} \times C_{out}) = 27 \times C_{in} \times C_{out}$
其中$C_{in}$和$C_{out}$分别是输入和输出通道数。
此外,多个非线性激活函数的引入也增强了模型的表达能力。例如,三个带ReLU的3×3卷积层的非线性表达能力强于一个带ReLU的7×7卷积层。
VGG网络的前向传播可以表示为:
$$x_{l+1} = \text{MaxPool}(f(W_l * x_l + b_l))$$
其中$x_l$是第$l$层的输入,$W_l$和$b_l$是第$l$层的权重和偏置,$f$是ReLU激活函数,$*$表示卷积操作,$\text{MaxPool}$是最大池化操作。
3.3.4 创新点与贡献
VGG网络的主要创新点和贡献包括:
深度增加:VGG网络将CNN的深度推向了新的高度(16-19层),证明了增加网络深度能够提高模型性能。
小卷积核:使用3×3的小卷积核代替大卷积核,减少参数数量,增加非线性表达能力。
简洁统一的架构:所有卷积层和池化层使用相同的参数设置,使网络结构更加规整和易于理解。
预训练与迁移学习:VGG网络在ImageNet上的预训练模型被广泛用于其他计算机视觉任务,推动了迁移学习的发展。
特征提取器:VGG网络的中间层特征被证明对于各种视觉任务非常有效,成为了计算机视觉领域的通用特征提取器。
VGG网络虽然结构简单,但由于其庞大的参数量和计算量,在实际应用中面临着存储和计算效率的挑战。尽管如此,VGG网络的设计理念和架构特点对后续CNN的发展产生了深远影响,其预训练模型至今仍被广泛应用于各种计算机视觉任务。
随着VGG等模型将网络深度推向新高度,研究者们开始关注另一个关键问题:如何在保持或提高性能的同时,降低模型的计算复杂度和参数量?GoogLeNet通过创新的Inception模块和网络设计,为这一问题提供了全新的思路。
3.4 GoogLeNet/Inception (2014)
GoogLeNet是由Google研究团队在2014年提出的深度卷积神经网络,以”Going Deeper with Convolutions”为题发表在CVPR 2014会议上。该网络在2014年的ILSVRC比赛中获得了分类任务的冠军,将Top-5错误率降低到了6.67%。GoogLeNet以计算机科学家Yann LeCun的致敬命名,同时也暗示了网络的”深度”特性。
3.4.1 问题背景
随着CNN架构不断加深和加宽,研究者们面临着计算效率和模型规模的严峻挑战:
- 计算资源瓶颈:VGG等模型虽然性能优异,但参数量巨大(1.38亿),计算和存储成本高昂
- 特征多样性不足:单一尺寸的卷积核难以捕获不同尺度的特征
- 网络退化问题:简单地增加网络深度并不总是能提高性能,有时反而会导致性能下降
- 实际部署困难:大型模型在资源受限的环境中难以部署
GoogLeNet通过创新的Inception模块解决了这些问题,它允许网络同时学习多尺度特征,并通过1×1卷积进行降维,大大提高了计算效率。GoogLeNet在保持较低参数量(约700万,仅为VGG的5%)的同时,实现了更高的准确率。
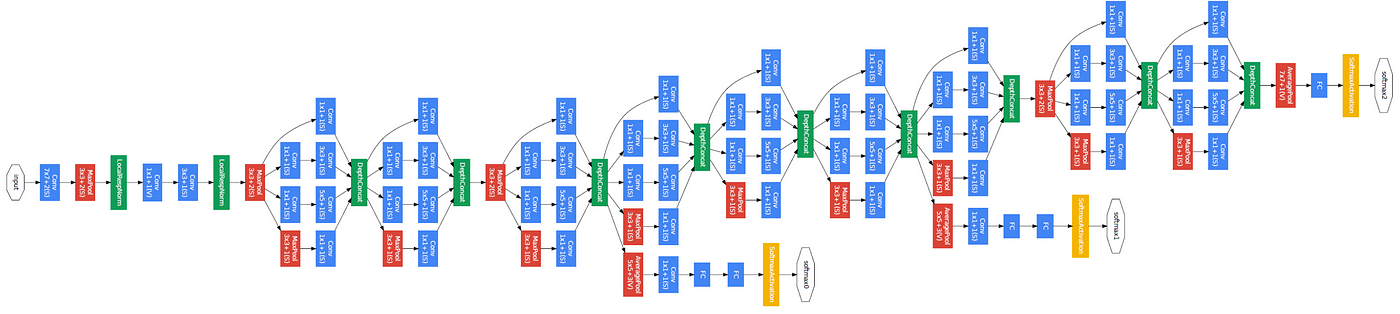
3.4.2 网络结构
GoogLeNet的核心创新是引入了”Inception模块”,这是一种多路径的网络结构,允许在同一层中使用不同大小的卷积核并行提取特征。完整的GoogLeNet包含9个Inception模块,总共22层(如果只计算带参数的层)。
GoogLeNet的整体结构如下:
- 输入层:224×224×3的RGB图像
- 初始卷积层:
- 7×7卷积,步长为2,64个卷积核,输出112×112×64
- 3×3最大池化,步长为2,输出56×56×64
- 降维卷积层:
- 1×1卷积,64个卷积核,输出56×56×64
- 3×3卷积,192个卷积核,输出56×56×192
- 3×3最大池化,步长为2,输出28×28×192
- Inception模块(3a-3b):
- Inception(3a):输出28×28×256
- Inception(3b):输出28×28×480
- 3×3最大池化,步长为2,输出14×14×480
- Inception模块(4a-4e):
- Inception(4a):输出14×14×512
- Inception(4b):输出14×14×512
- Inception(4c):输出14×14×512
- Inception(4d):输出14×14×528
- Inception(4e):输出14×14×832
- 3×3最大池化,步长为2,输出7×7×832
- Inception模块(5a-5b):
- Inception(5a):输出7×7×832
- Inception(5b):输出7×7×1024
- 全局平均池化:输出1×1×1024
- Dropout层:Dropout率为0.4
- 全连接层:1000个神经元,Softmax激活
GoogLeNet还包含两个辅助分类器,连接在Inception(4a)和Inception(4d)之后,用于在训练过程中提供额外的梯度信号,缓解梯度消失问题。这些辅助分类器在测试时被丢弃。
3.4.3 Inception模块
Inception模块是GoogLeNet的核心组件,其设计思想是在同一层中并行使用不同大小的卷积核,以捕获不同尺度的特征。一个基本的Inception模块包含四条并行路径:
- 1×1卷积
- 1×1卷积 → 3×3卷积
- 1×1卷积 → 5×5卷积
- 3×3最大池化 → 1×1卷积
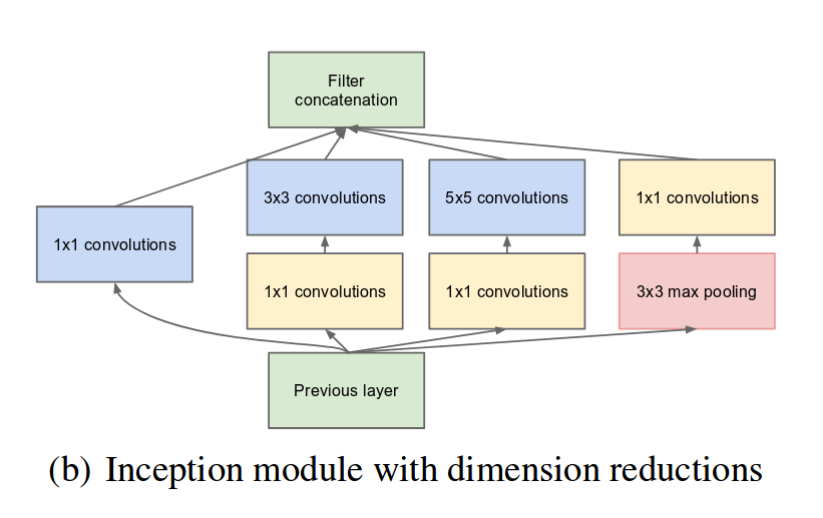
其中,1×1卷积主要用于降维,减少计算量。例如,在第二条路径中,如果输入特征图有256个通道,我们可以先用64个1×1的卷积核将通道数降到64,再用128个3×3的卷积核进行卷积,这样计算量比直接用128个3×3的卷积核在256个通道上进行卷积要小得多。
数学上,Inception模块的计算可以表示为:
$$\text{Inception}(x) = \text{Concat}(f_{1\times1}(x), f_{3\times3}(f_{1\times1}^{reduce}(x)), f_{5\times5}(f_{1\times1}^{reduce}(x)), f_{1\times1}^{pool}(\text{MaxPool}(x)))$$
其中:
- $f_{k\times k}$ 表示使用 $k\times k$ 卷积核的卷积操作
- $f_{1\times1}^{reduce}$ 表示用于降维的1×1卷积
- $f_{1\times1}^{pool}$ 表示池化后的1×1卷积
- $\text{Concat}$ 表示在通道维度上的拼接操作
3.4.4 辅助分类器
为了解决深度网络中的梯度消失问题,GoogLeNet引入了辅助分类器。这些分类器连接在中间层,在训练过程中提供额外的梯度信号。每个辅助分类器包含:
- 5×5平均池化,步长为3
- 1×1卷积,128个卷积核
- 全连接层,1024个神经元,ReLU激活
- Dropout层,Dropout率为0.7
- 全连接层,1000个神经元,Softmax激活
辅助分类器的损失函数乘以0.3的权重,与主分类器的损失函数一起构成总损失函数:
$$L_{total} = L_{main} + 0.3 \times (L_{aux1} + L_{aux2})$$
3.4.5 创新点与贡献
GoogLeNet的主要创新点和贡献包括:
Inception模块:通过并行使用不同大小的卷积核,能够在同一层中捕获不同尺度的特征,增强了网络的表达能力。
1×1卷积降维:使用1×1卷积进行降维,大大减少了计算量和参数数量,使得网络能够更深更宽,同时保持计算效率。
全局平均池化:用全局平均池化代替全连接层,大大减少了参数数量,同时保持了性能。
辅助分类器:通过在中间层添加辅助分类器,缓解了深度网络中的梯度消失问题,使得更深的网络能够有效训练。
高效的网络设计:尽管GoogLeNet比VGG-16/19更深(22层vs 16/19层),但其参数数量只有约700万,远少于VGG的1.38亿,计算效率更高。
GoogLeNet的成功证明了网络设计的重要性,通过精心设计的网络结构,可以在保持或提高性能的同时,大大减少参数数量和计算量。Inception模块的思想被广泛应用于后续的CNN架构中,并衍生出了一系列改进版本,如Inception-v2、Inception-v3、Inception-v4和Inception-ResNet等。
尽管GoogLeNet等模型在网络设计上取得了重要进展,但随着网络深度的进一步增加,研究者们发现了一个令人困惑的现象:更深的网络反而导致性能下降,即使在训练集上也是如此。这一”退化问题”成为了深度网络研究的新挑战,ResNet通过引入残差学习的创新理念,成功突破了这一瓶颈。
3.5 ResNet (2015)
ResNet(残差网络)是由微软研究院的何恺明(Kaiming He)等人在2015年提出的深度卷积神经网络,以”Deep Residual Learning for Image Recognition”为题发表在CVPR 2016会议上。该网络在2015年的ILSVRC比赛中获得了分类任务的冠军,将Top-5错误率降低到了3.57%,接近人类水平。ResNet的核心创新是引入了”残差学习”的概念,成功解决了深度网络训练中的退化问题,使得训练超过100层甚至1000层的网络成为可能。
3.5.1 问题背景
随着研究者不断增加网络深度,一个反直觉的现象被观察到:网络深度增加到一定程度后,训练误差反而上升。这一现象被称为”退化问题”(degradation problem),它不是由过拟合引起的(因为训练误差也增加),而是由于深层网络优化困难导致的。具体挑战包括:
- 梯度消失/爆炸:尽管批量归一化等技术缓解了这一问题,但超深网络中梯度传播仍然困难
- 优化困难:深层网络的损失函数更加复杂,优化算法容易陷入局部最优
- 退化问题:理论上,更深的网络至少应该和浅层网络一样好(可以通过将额外层设为恒等映射),但实际上深层网络性能反而下降
- 表示瓶颈:传统前馈网络结构可能限制了信息流动和特征重用
ResNet通过引入残差连接(跳跃连接)巧妙地解决了这些问题,使得网络可以直接学习残差映射,大大简化了优化过程,成功训练了152层甚至更深的网络。
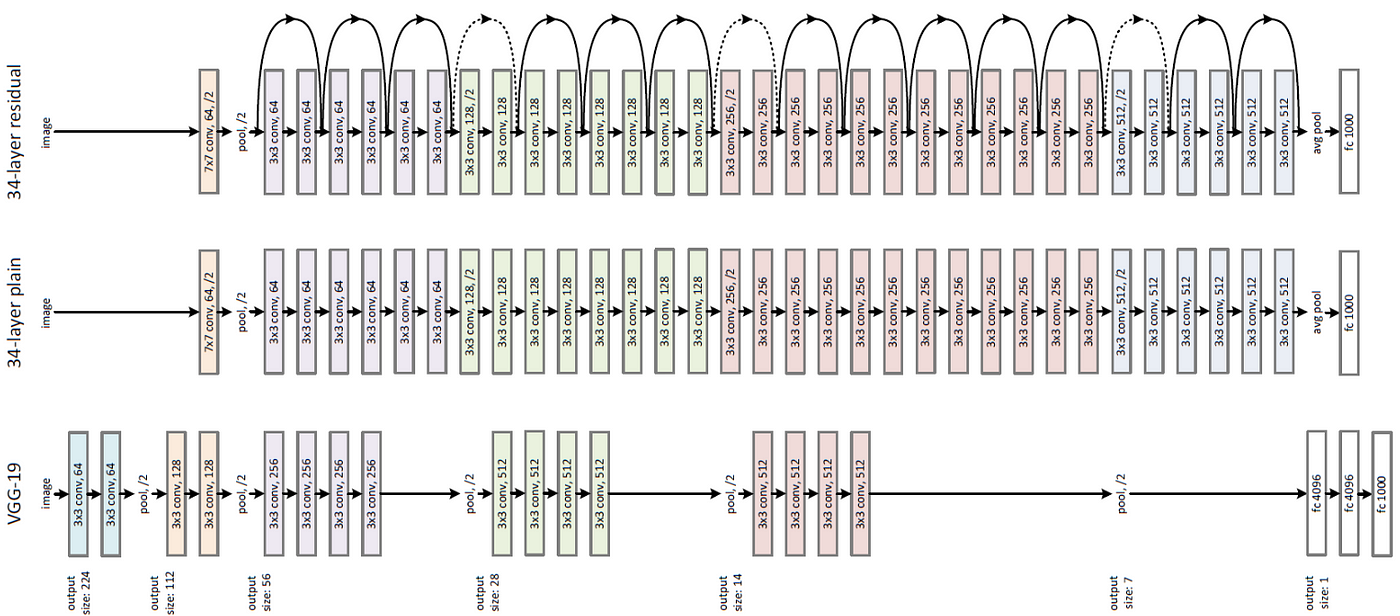
3.5.2 网络结构
ResNet有多个变体,包括ResNet-18/34/50/101/152,数字表示网络的层数。以ResNet-50为例,其结构如下:
初始层:
- 7×7卷积,步长为2,64个卷积核
- 3×3最大池化,步长为2
残差块堆叠:
- conv2_x:3个瓶颈残差块,输出通道数64
- conv3_x:4个瓶颈残差块,输出通道数128
- conv4_x:6个瓶颈残差块,输出通道数256
- conv5_x:3个瓶颈残差块,输出通道数512
全局平均池化
全连接层:1000个神经元(对应ImageNet的1000个类别)
ResNet-18和ResNet-34使用基本残差块(Basic Block),而ResNet-50/101/152使用瓶颈残差块(Bottleneck Block)以提高计算效率。
3.5.3 残差块设计
ResNet的核心创新是残差块(Residual Block)的设计。残差块可以表示为:
$$y = F(x, {W_i}) + x$$
其中$x$是输入,$F(x, {W_i})$是残差映射,$y$是输出。残差块有两种主要形式:
基本残差块(Basic Block):
- 3×3卷积 → 批量归一化 → ReLU
- 3×3卷积 → 批量归一化
- 跳跃连接(将输入直接加到输出)
- ReLU
瓶颈残差块(Bottleneck Block):
- 1×1卷积(降维)→ 批量归一化 → ReLU
- 3×3卷积 → 批量归一化 → ReLU
- 1×1卷积(升维)→ 批量归一化
- 跳跃连接(将输入直接加到输出)
- ReLU
当输入和输出的维度不同时,跳跃连接需要进行投影变换,通常通过1×1卷积实现。
3.5.4 数学原理
ResNet的核心思想是学习残差映射而非直接映射。假设我们希望某些层学习的理想映射是$H(x)$,ResNet让这些层学习残差映射$F(x) = H(x) - x$,这样原始映射变为$H(x) = F(x) + x$。
这种设计基于一个假设:学习残差映射比学习原始映射更容易。特别是,如果理想映射接近于恒等映射,则残差$F(x)$接近于零,这比通过多层非线性函数拟合恒等映射要容易得多。
从优化角度看,残差连接为梯度提供了一条直接的反向传播路径,缓解了深层网络中的梯度消失问题。具体来说,根据链式法则,残差块的梯度可以表示为:
$$\frac{\partial \mathcal{L}}{\partial x} = \frac{\partial \mathcal{L}}{\partial y} \cdot \frac{\partial y}{\partial x} = \frac{\partial \mathcal{L}}{\partial y} \cdot \left(\frac{\partial F(x)}{\partial x} + 1\right)$$
其中$\mathcal{L}$是损失函数。即使$\frac{\partial F(x)}{\partial x}$接近于零,梯度$\frac{\partial \mathcal{L}}{\partial x}$也不会消失,因为有一个恒等项”1”。
3.5.5 创新点与贡献
ResNet的主要创新点和贡献包括:
残差学习:通过学习残差映射而非直接映射,大大简化了深层网络的优化过程。
跳跃连接:创建了信息和梯度的直接通路,有效缓解了梯度消失问题。
突破深度限制:成功训练了152层甚至1000多层的网络,证明了增加深度确实能提高模型性能。
性能突破:在ILSVRC 2015比赛中获得冠军,Top-5错误率降至3.57%,接近人类水平。
广泛应用:ResNet的设计理念被广泛应用于各种计算机视觉任务,如目标检测(Faster R-CNN)、语义分割(DeepLab)等。
启发后续研究:启发了许多后续工作,如ResNeXt、Wide ResNet、DenseNet等。
ResNet的成功对深度学习领域产生了深远影响,它不仅突破了深度限制,还启发了许多后续工作,如ResNeXt、Wide ResNet和DenseNet等。残差连接的思想也已扩展到自然语言处理、语音识别等其他领域。
如果您想深入了解ResNet的原理、架构和创新点,请参阅我的ResNet专题博客,其中详细解析了残差学习的数学原理、网络结构设计以及为什么残差连接能有效解决深度网络的退化问题。
ResNet解决了深度网络的训练问题,但其简单的跳跃连接结构仍有优化空间。研究者们开始思考:是否有更高效的方式来利用特征和促进梯度流动?这一思考催生了新一代CNN架构的发展,如DenseNet等现代网络设计。
4. 现代CNN架构
在ResNet之后,CNN架构的研究进入了一个新的阶段,研究者们不仅追求更高的准确率,还关注模型的效率、可解释性和适用性。ResNet解决了深度网络训练的关键问题,为更深更复杂的网络设计铺平了道路。现代CNN架构在此基础上,探索了特征重用、模型轻量化、高效缩放等多个方向,进一步推动了CNN的发展和应用。本节将介绍一些代表性的现代CNN架构。
4.1 DenseNet (2017)
DenseNet(密集连接网络)是由黄高(Gao Huang)等人在2017年提出的,其核心思想是在网络中引入密集连接,使得每一层都直接连接到之前的所有层。
4.1.1 问题背景
ResNet的成功证明了创建信息和梯度的直接通路对训练深度网络至关重要。然而,研究者们发现仍有改进空间:
- 特征重用效率:ResNet中的特征可能存在冗余,未充分利用已学习的特征
- 梯度流动:尽管ResNet缓解了梯度消失问题,但梯度仍需通过多层传播
- 参数效率:深层网络参数利用率不高,存在冗余计算
- 特征多样性:如何在不同抽象层次上有效组合特征仍是挑战
DenseNet通过密集连接模式解决了这些问题,它不仅创建了更短的梯度路径,还实现了特征的极致重用,使得网络能够用更少的参数达到更好的性能。DenseNet在图像分类、目标检测等任务上取得了优异成绩,同时具有更好的参数效率和计算效率。

4.1.2 网络结构
DenseNet由多个密集块(Dense Block)和过渡层(Transition Layer)组成:
- 密集块:每一层的输入是前面所有层的特征图的拼接,输出的特征图会被传递给后续所有层作为输入。
- 过渡层:位于两个密集块之间,用于降低特征图的空间维度,包含批量归一化、1×1卷积和2×2平均池化。
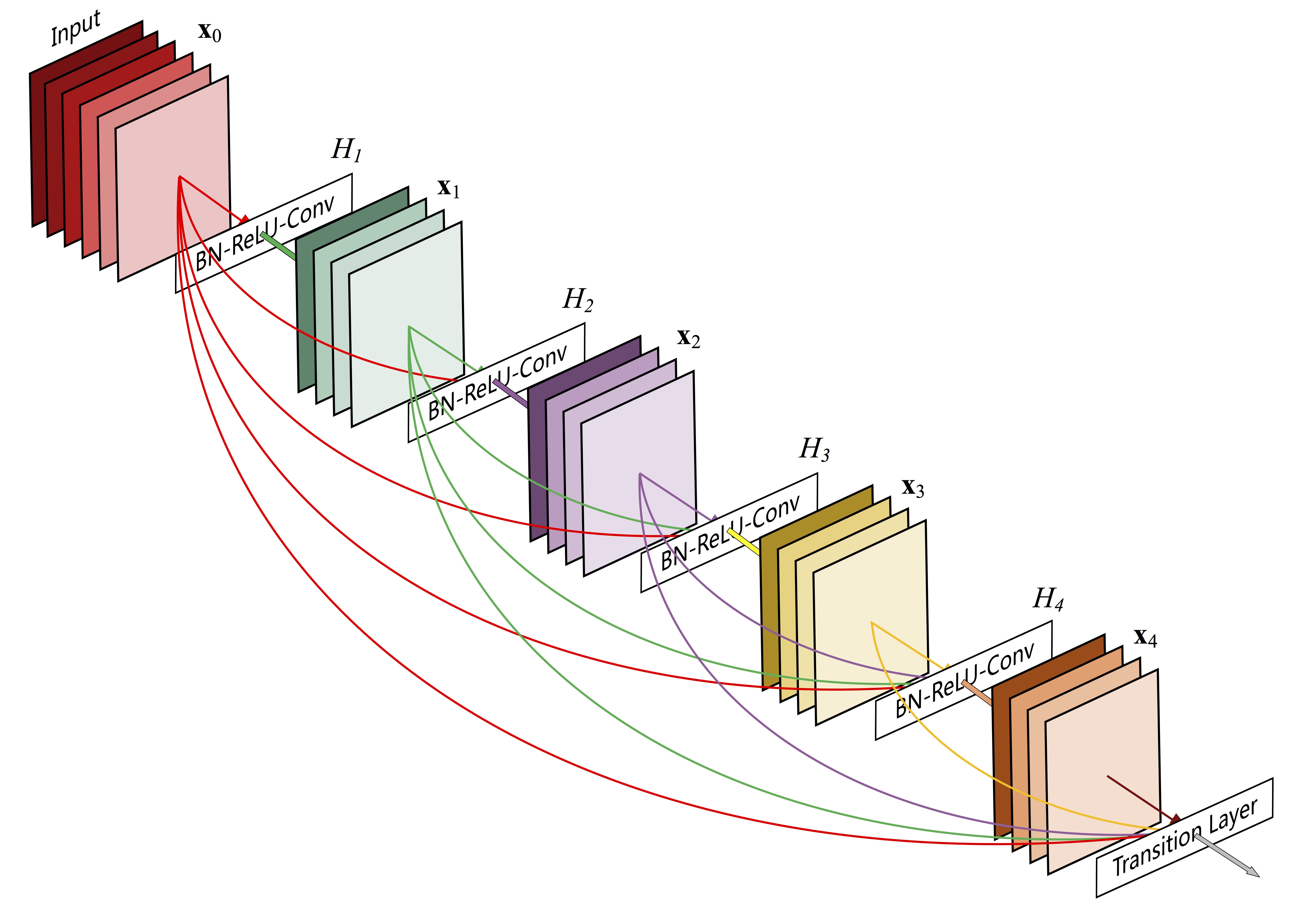
DenseNet的数学表达式为:
$$x_l = H_l([x_0, x_1, …, x_{l-1}])$$
其中 $x_l$ 是第 $l$ 层的输出,$[x_0, x_1, …, x_{l-1}]$ 表示前面所有层输出的拼接,$H_l$ 是一个复合函数,包含批量归一化、ReLU激活和卷积。
4.1.3 创新点与贡献
DenseNet的主要创新点和贡献包括:
- 密集连接:每一层都直接连接到之前的所有层,促进了特征重用,增强了梯度流动。
- 减少参数数量:通过特征重用,DenseNet减少了冗余特征的学习,参数数量比同等性能的ResNet少。
- 缓解梯度消失:密集连接为梯度提供了多条直接的反向传播路径,进一步缓解了梯度消失问题。
- 特征多样性:每一层都可以访问不同抽象级别的特征,增强了特征的多样性。
DenseNet在提高模型性能和参数效率方面取得了重要进展,但随着深度学习应用场景的多样化,特别是移动和嵌入式设备的普及,对轻量级高效CNN的需求日益增长。MobileNet系列应运而生,专注于在资源受限环境下的高效视觉识别。
4.2 MobileNet (2017-2019)
MobileNet是由Google研究团队开发的一系列轻量级CNN架构,专为移动和嵌入式设备设计。MobileNet系列包括MobileNetV1(2017)、MobileNetV2(2018)和MobileNetV3(2019)。
4.2.1 问题背景
随着深度学习在移动设备和物联网应用的普及,对轻量级高效CNN的需求日益增长。然而,主流CNN架构如ResNet、DenseNet等虽然性能优异,但计算量和参数量巨大,难以在资源受限的设备上运行。具体挑战包括:
- 计算资源限制:移动设备的处理能力、内存和电池容量有限
- 实时性要求:许多移动应用(如AR/VR、实时翻译)需要低延迟
- 模型大小限制:移动应用对模型存储空间有严格限制
- 能耗考量:移动设备需要节能运行,减少电池消耗
MobileNet系列通过创新的网络架构设计,特别是深度可分离卷积,成功地在保持较高准确率的同时,大幅降低了计算量和参数量,使得高质量的视觉识别能够在移动设备上实时运行。
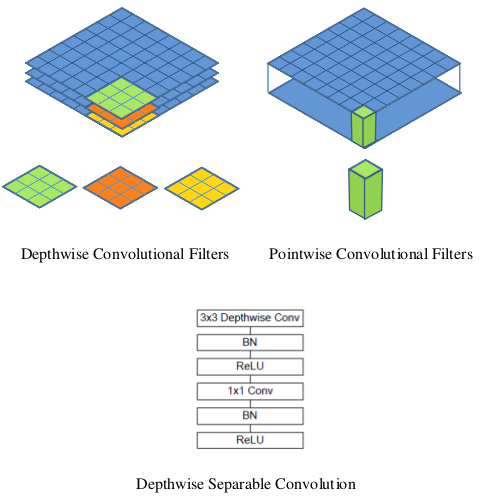
4.2.2 深度可分离卷积
MobileNet的核心创新是引入深度可分离卷积(Depthwise Separable Convolution),将标准卷积分解为深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两步:
- 深度卷积:对输入的每个通道单独应用一个卷积核,输出通道数与输入相同。
- 逐点卷积:使用1×1卷积核对深度卷积的输出进行通道间的组合。
深度可分离卷积大大减少了计算量和参数数量:
- 标准卷积的计算量:$D_K \times D_K \times M \times N \times D_F \times D_F$
- 深度可分离卷积的计算量:$D_K \times D_K \times M \times D_F \times D_F + M \times N \times D_F \times D_F$
其中 $D_K$ 是卷积核大小,$M$ 是输入通道数,$N$ 是输出通道数,$D_F$ 是特征图大小。
4.2.3 MobileNetV2的改进
MobileNetV2引入了倒置残差结构(Inverted Residual Block)和线性瓶颈(Linear Bottleneck):
- 倒置残差结构:先通过1×1卷积扩展通道数,再进行深度卷积,最后通过1×1卷积压缩通道数。
- 线性瓶颈:在残差连接的末端不使用ReLU激活,以保留低维特征的信息。
4.2.4 MobileNetV3的改进
MobileNetV3结合了神经架构搜索(Neural Architecture Search)和人工设计,引入了:
- 硬Swish激活函数:$h\text{-swish}(x) = x \cdot \text{ReLU6}(x+3)/6$,计算效率更高。
- 注意力机制:引入Squeeze-and-Excitation模块,增强重要通道的特征。
- 网络修剪:移除对性能贡献小的层和操作。
4.2.5 创新点与贡献
MobileNet系列的主要创新点和贡献包括:
- 深度可分离卷积:大大减少了计算量和参数数量,使CNN能够在资源受限的设备上高效运行。
- 倒置残差结构:通过先扩展后压缩的方式,在保持表达能力的同时减少计算量。
- 线性瓶颈:避免了ReLU对低维特征的信息损失。
- 硬件感知模型设计:考虑了实际硬件的特性,优化模型在特定设备上的性能。
MobileNet系列解决了CNN在移动设备上的部署问题,但如何为不同计算预算设计最优模型仍是一个挑战。EfficientNet通过系统研究模型缩放策略,提出了一种更加科学和高效的方法来平衡模型大小和性能。
4.3 EfficientNet (2019)
EfficientNet是由Google研究团队在2019年提出的,通过系统地平衡网络的宽度、深度和分辨率,实现了更高效的模型缩放。
4.3.1 问题背景
随着CNN架构的不断发展,研究者们发现提高模型性能的方法主要有三种:增加网络深度、增加网络宽度(通道数)和增加输入分辨率。然而,如何有效地组合这三种方法以获得最佳性能和效率一直是一个挑战:
- 缩放策略不明确:之前的工作通常只关注其中一个维度的缩放,缺乏系统的方法
- 资源利用不均衡:单一维度缩放可能导致计算资源分配不均,效率低下
- 架构设计繁琐:为不同计算预算手动设计不同大小的模型工作量大
- 性能瓶颈:简单地增加某一维度可能会遇到收益递减
EfficientNet通过提出复合缩放方法(Compound Scaling),系统地研究了深度、宽度和分辨率三个维度的关系,找到了它们之间的最佳平衡点。同时,EfficientNet还使用神经架构搜索技术设计了高效的基础网络(EfficientNet-B0),然后通过复合缩放方法扩展到不同大小的模型(B1-B7),在各种计算预算下都取得了最先进的性能。
4.3.2 复合缩放方法
EfficientNet的核心创新是复合缩放方法(Compound Scaling Method),同时缩放网络的宽度(通道数)、深度(层数)和分辨率(输入图像大小):
$$\text{depth}: d = \alpha^\phi$$
$$\text{width}: w = \beta^\phi$$
$$\text{resolution}: r = \gamma^\phi$$
$$\text{s.t. } \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2$$
$$\alpha \geq 1, \beta \geq 1, \gamma \geq 1$$
其中 $\phi$ 是复合系数,用于控制可用资源的总量,$\alpha$、$\beta$ 和 $\gamma$ 是通过小型网格搜索确定的常数。
4.3.3 创新点与贡献
EfficientNet的主要创新点和贡献包括:
- 复合缩放方法:系统地平衡网络的宽度、深度和分辨率,实现更高效的模型缩放。
- MBConv块:使用MobileNetV2中的移动倒置瓶颈卷积(Mobile Inverted Bottleneck Convolution)作为基本构建块。
- Swish激活函数:使用Swish激活函数 $f(x) = x \cdot \sigma(x)$,其中 $\sigma(x)$ 是sigmoid函数。
- 高效性能:在相同的计算预算下,EfficientNet比之前的CNN架构实现了更高的准确率。
4.4 其他现代CNN架构
除了上述架构外,还有许多其他值得关注的现代CNN架构:
ResNeXt (2017):在ResNet的基础上引入了分组卷积(Grouped Convolution),增加了网络的宽度,同时保持计算复杂度。
SENet (2018):引入了Squeeze-and-Excitation模块,通过显式建模通道间的相互依赖关系,自适应地调整通道特征的重要性。
ShuffleNet (2018):结合了逐点分组卷积和通道重排(Channel Shuffle),在保持准确率的同时大大减少了计算量。
NASNet (2018):使用强化学习进行神经架构搜索,自动设计CNN架构,取得了当时最先进的性能。
EfficientNetV2 (2021):在EfficientNet的基础上进一步优化,引入了Fused-MBConv块和渐进式学习策略,提高了训练效率和准确率。
4.5 最新CNN发展趋势 (2022-2024)
随着Transformer在计算机视觉领域的成功应用(如Vision Transformer),CNN架构也在不断创新和演进,吸收Transformer的优点并保持CNN的高效性。以下是近年来CNN发展的最新趋势:
4.5.1 ConvNeXt (2022)
ConvNeXt是由Facebook AI Research团队提出的,旨在通过纯卷积网络架构实现与Vision Transformer相当的性能。ConvNeXt系统地研究了现代CNN设计策略,将Transformer的设计理念应用到CNN架构中。
主要创新点包括:
- 宏观设计:采用类似Transformer的阶段式设计,每个阶段保持特征图分辨率不变
- 卷积块设计:使用深度卷积(7×7替代3×3)增大感受野
- 微观设计:调整激活函数(GELU替代ReLU)、归一化层(Layer Norm替代Batch Norm)和下采样策略
- 训练策略:采用与ViT类似的训练方法,如AdamW优化器、更长的训练周期等
ConvNeXt证明了经过现代化设计的CNN仍然具有强大的竞争力,在ImageNet分类、COCO目标检测和ADE20K语义分割等任务上取得了与Swin Transformer相当的性能,同时保持了CNN的高效推理特性。
4.5.2 ConvNeXt V2 (2023)
ConvNeXt V2是ConvNeXt的改进版本,引入了全局响应归一化(Global Response Normalization, GRN)模块,进一步提高了模型性能。GRN模块通过对特征进行全局上下文建模,增强了模型捕获长距离依赖的能力,同时保持了计算效率。
ConvNeXt V2在保持纯卷积架构的同时,在ImageNet-1K上达到了87.8%的Top-1准确率,超过了许多Transformer-based模型,证明了CNN架构在现代视觉任务中的持续竞争力。
4.5.3 CNN与Transformer的混合模型
除了纯CNN架构的改进,研究者们也在探索CNN与Transformer结合的混合架构,结合两者的优势:
CoAtNet (2021):结合了卷积的归纳偏置和Transformer的长距离建模能力,在ImageNet分类和COCO目标检测上取得了优异性能。
MobileViT (2022):将轻量级CNN与Transformer结合,为移动设备设计的高效视觉模型,在保持低计算复杂度的同时实现了强大的表示能力。
MaxViT (2022):提出了多轴注意力(Multi-Axis Attention)机制,结合了局部和全局注意力,在各种视觉任务上取得了最先进的性能。
InternImage (2023):引入了可变形卷积(Deformable Convolution)与Transformer结合的架构,在COCO目标检测和ADE20K语义分割等任务上取得了最先进的性能。
4.5.4 自监督学习与基础模型
最新的CNN研究也在探索自监督学习和基础模型(Foundation Models)方向:
ConvMAE (2022):将掩码自编码器(Masked Autoencoder)技术应用于CNN架构,实现了高效的自监督预训练。
DINOv2 (2023):使用自蒸馏和对比学习技术,训练了具有强大迁移能力的视觉基础模型,在多种下游任务上表现优异。
ConvNet-based SAM (2023):基于CNN的分割任何物体(Segment Anything Model)变体,保持高精度的同时提高推理效率。
这些最新发展表明,尽管Transformer在视觉领域取得了巨大成功,CNN仍然是计算机视觉的重要基石,并在不断吸收新技术和理念进行创新。CNN与Transformer的融合代表了视觉模型的未来发展方向,结合两者的优势,创造更加强大、高效的视觉表示学习模型。
5. 总结
卷积神经网络自LeNet-5问世以来,经历了长足的发展,从AlexNet的突破性成功,到VGG的深度探索,再到GoogLeNet的多尺度特征提取,以及ResNet的残差学习,每一步都推动了深度学习在计算机视觉领域的进步。现代CNN架构如DenseNet、MobileNet和EfficientNet等,则进一步优化了模型的效率和性能,使CNN能够在各种应用场景中发挥作用。
CNN已在图像分类、目标检测、语义分割、人脸识别和医学图像分析等众多领域取得了显著成功。尽管如此,CNN仍面临一些挑战,如对空间变换的敏感性、全局上下文信息捕获的局限、计算资源需求大、对标注数据的依赖以及可解释性不足等问题。
随着研究的深入和技术的进步,CNN将继续在计算机视觉和其他领域发挥重要作用。未来的CNN可能会更加高效、更加智能、更加可解释,并与其他技术如Transformer、图神经网络等结合,聚焦于自监督学习和自动化架构搜索等方向,开创人工智能的新篇章。
参考文献
[1] LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
[2] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
[3] Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[4] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., … & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
[5] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[6] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
[7] Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., … & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
[8] Tan, M., & Le, Q. (2019). Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (pp. 6105-6114). PMLR.
[9] Xie, S., Girshick, R., Dollár, P., Tu, Z., & He, K. (2017). Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1492-1500).
[10] Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132-7141).